mysql一主多从以及使用springboot aop进行读写分离的搭建的正确姿式
介绍
这是一篇高度集中火力的生产环境中的mysql5.7一主多从以及结合spring boot进行读写分离的最全文档。主末笔者还会给出一个完整的基于spring boot的使用aop特性做完整项目读写分离的全代码与演示。
本文涉及技术点如下:
- mysql5.7.30+版本
- spring boot
- AOP
- haproxy
- keep alive
1.目标
mySQL层1主挂多从
安装3台mysql服务器,三台服务分布如下:
mySQL master: 192.168.2.101
mySQL slaver1: 192.168.2.102
mySQL slaver2: 192.168.2.103
HAProxy层主备
对外以22306端口反向代理2个mySQL的slaver
ha master: 192.168.2.102
ha slaver: 192.168.2.103
Keepalived层主备以及虚出一个ip叫192.168.2.201来供应用层调用
应用层无感知虚ip下挂几台mysql
keepalived master: 192.168.2.102
keepalived slaver: 192.168.2.103
keepalived出来的vip:192.168.2.201
设计spring boot应用程序框架内内置aop切片根据service层方法名决定读写路由
设计一个spring boot,用aop+auto config来实现根据xxx.service.方法名,自动让应用层所有的get/select方法走slaver, add/update/del/insert/delete等方法走master。
该框架内可以实现至少2个基于druid的jdbc数据源,一个叫master, 一个叫slaver。数据库层读写分离需要做到程序员无感。
2.安装三台mySQL服务器
centos7.x(此处我用的是centos7.4)安装mysql5.7过程
第一步,安装mysql5.7 yum源:
wget http://dev.mysql.com/get/mysql57-community-release-el7-8.noarch.rpm
yum localinstall mysql57-community-release-el7-8.noarch.rpm第二步,验证yum源是否正确:
yum repolist enabled | grep "mysql.*-community.*”第三步,安装mysql:
yum install mysql-community-server第四步,设置开机启动
systemctl enable mysqld
systemctl start mysqld把3台mysql先按照上述方式全部装完,正常启动后
第五步,设置远程root登录
grep 'temporary password' /var/log/mysqld.log
我们可以看到,这边有一个随机密码在:is generated for root@localhost:后,这个是mysql5.7开始在安装后默认生成的一个初始root密码,我们把它复制一下。
然后用它来登录我们刚装好的mysql
mysql -uroot -pALTER USER 'root'@'localhost' IDENTIFIED BY '111111';注意:mysql5.7默认安装了密码安全检查插件(validate_password),默认密码检查策略要求密码必须包含:大小写字母、数字和特殊符号,并且长度不能少于8位。否则会提示ERROR 1819 (HY000): Your password does not satisfy the current policy requirements错误,如下图所示:

因为是演练环境,我们可以暂时让我们的mysql5.7的root密码变得简单,因此我们先让这个默认的密码策略变得极其简单
set global validate_password_policy=0;
set global validate_password_length=0;接下去我们继续添加远程用
ALTER USER 'root'@'localhost' IDENTIFIED BY '111111';
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '111111' WITH GRANT OPTION;
FLUSH PRIVILEGES;把三台mySQL都按照上述步骤设好了,然后拿mySQL客户端都验证一下可登录性操作。
第六步,设置时间同步
我们把192.168.2.101这台master设置成时间服务器,然后把192.168.2.102以及192.168.2.103设成192.168.2.101的被同步子时间节点。
在192.168.2.101上做如下设置(本次实验环境,因此我们把时间服务器设成ali的时间服务器,地址如下:ntp1.aliyun.co
yum -y install ntp
vim /etc/ntp.conf
#注释掉所有server *.*.*的指向,新添加一条可连接的ntp服务器 我使用的是阿里云的NTP服务器
server ntp1.aliyun.com ymklinux1
#在其他节点上把ntp指向master服务器地址即可
server 192.168.2.101 ymklinux1
#安装完成后设置ntp开机启动并启动ntp
systemctl enable ntpd
systemctl start ntpd
#查看状态
systemctl status ntpd注意:各时间子节点设完同步时间服务后要记得运行一下这条命令
|
|

第七步,开始配置三个mysql上的my.cnf文件
它位于/etc/my.cnf文件这个位置。每个mysql里的my.cnf文件使得其内容相同即
# For advice on how to change settings please see
# http://dev.mysql.com/doc/refman/5.7/en/server-configuration-defaults.html
[mysqld]
#
# Remove leading # and set to the amount of RAM for the most important data
# cache in MySQL. Start at 70% of total RAM for dedicated server, else 10%.
# innodb_buffer_pool_size = 128M
#
# Remove leading # to turn on a very important data integrity option: logging
# changes to the binary log between backups.
# log_bin
#
# Remove leading # to set options mainly useful for reporting servers.
# The server defaults are faster for transactions and fast SELECTs.
# Adjust sizes as needed, experiment to find the optimal values.
# join_buffer_size = 128M
# sort_buffer_size = 2M
# read_rnd_buffer_size = 2M
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
port=3306
character-set-server=utf8
innodb_buffer_pool_size=2G
max_connections = 800
max_allowed_packet = 128M
max_heap_table_size = 256M
tmp_table_size = 256M
innodb_buffer_pool_chunk_size = 256M
innodb_buffer_pool_instances = 8
innodb_thread_concurrency = 4
#(核心交易系统设置为1,默认为1,其他2或者0)
innodb_flush_log_at_trx_commit=2核心参数讲解:
- character-set-server=utf8 字符集设成UTF8
- innodb_buffer_pool_size=2G mysql核心innodb引擎参数之缓冲池,这个值一般可以为OS的70%,它和oracle的share_pool_size功能一样,设至大小将直接影响你的查询效率,因为是演示环境,因此不用太大,够用就行。
- max_connections = 800 数据库最大连接数
- max_allowed_packet = 128M 一次查询返回的结果集可允许的最大厦size
- max_heap_table_size = 256M 先说下tmp_table_size吧:它规定了内部内存临时表的最大值,每个线程都要分配。(实际起限制作用的是tmp_table_size和max_heap_table_size的最小值。)如果内存临时表超出了限制,MySQL就会自动地把它转化为基于磁盘的MyISAM表,存储在指定的tmpdir目录下,默认:优化查询语句的时候,要避免使用临时表,如果实在避免不了的话,要保证这些临时表是存在内存中的。如果需要的话并且你有很多group by语句,并且你有很多内存,增大tmp_table_size(和max_heap_table_size)的值。这个变量不适用与用户创建的内存表(memory table).
- tmp_table_size = 256M
- innodb_buffer_pool_chunk_size = 128M 此处我们使用默认配置
- innodb_buffer_pool_instances = 8 CPU数量
- innodb_thread_concurrency =8 不要超过CPU核数
- innodb_flush_log_at_trx_commit=2 #(核心交易系统设置为1,默认为1,其他2或者0),
0代表:log buffer将每秒一次地写入log file中,并且log file的flush(刷到磁盘)操作同时进行。该模式下在事务提交的时候,不会主动触发写入磁盘的操作。
1代表:每次事务提交时MySQL都会把log buffer的数据写入log file,并且flush(刷到磁盘)中去,该模式为系统默认(因此会保留每一份redo日志)
2代表:每次事务提交时MySQL都会把log buffer的数据写入log file,但是flush(刷到磁盘)操作并不会同时进行。该模式下,MySQL会每秒执行一次 flush(刷到磁盘)操作。该模式速度较快,也比0安全,只有在操作系统崩溃或者系统断电的情况下,上一秒钟所有事务数据才可能丢失。
3个mySQL都配置完后,记得全部重启Linux,下面我们要进入mySQL的1主多从的搭建了。
mySQL主从搭建
Master配置
修改my.cnf,在最后一行加入如下几行。
此处,演示环境我们对ecom这个schema做主从同步

#主从同步配置
server-id=1
log-bin=/var/lib/mysql/mysql-bin
binlog-do-db=ecom
validate_password=off注意:
- ID一定要为阿拉伯数字,血泪教训;
- 另外注意一点,这边为了演练环境方便,我把密码策略都给设成“傻瓜式”了。真式生产环境一定要小心;
Slaver1-192.168.2.102中追加的配置
此处我们对slaver开启了read_only=1,即在从上就不允许发生写操作。
server-id=2
log-bin=/var/lib/mysql/mysql-bin
relay-log-index=slave-relay-bin.index
relay-log=slave-relay-bin
replicate-do-db=ecom
log-slave-updates
slave-skip-errors=all
read_only=1
validate_password=offSlaver2-192.168.2.103中追加的配置
server-id=3
log-bin=/var/lib/mysql/mysql-bin
relay-log-index=slave-relay-bin.index
relay-log=slave-relay-bin
replicate-do-db=ecom
log-slave-updates
slave-skip-errors=all
read_only=1
validate_password=off创建用于复制主从数据的mysql用户
2个Slaver设完后记得重启mysql,记下来我们开始在master上创建一个mySQL用户,它用于同步主从用的。
set global validate_password_policy=0;
set global validate_password_length=0;
create user 'repl' identified by '111111';
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'192.168.2.%' identified by '111111';
flush privileges;使用master的binlog给到Slaver用于“追平”master上的数据
在master所在的centos7上,输入以下命令,把ecom这个schema全量导出。
mysqldump -u ecom -p 111111 -B -F -R -x ecom|gzip > /opt/mysql_backup/ecom_$(date +%Y%m%d_%H%M%S).sql.gz然后把它copy到两个slaver上-192.168.2.102和192.168.2.103上
接下来要做的事都是相同的
gzip -d ymkmysql_20200411_215500.sql.gz
mysql -u root -p < ymkmysql_20200411_215500.sql在两个slaver上追平主库后,开始进入真正的数据库级别的主从同步了。
先跑去master节点上,通过sqlclient
show master status;
记下这2个值来,然后我们跑到192.168.2.102上以及192.168.2.103上都做同样的一件事
stop slave;
reset slave;
change master to master_host='192.168.2.101',master_port=3306,master_user='repl',master_password='111111',master_log_file='mysql-bin.000013',master_log_pos=154;它的作用在于,把slaver上的binlog同步位置调成和master一致,调完后
start slave;
show slave status;
数据量小的情况下,几分钟就可以看到"slave_io_running"与"slave_sql_running"的状态为Yes了,这代表主从已经完成同步。
主从做完后我们来做个测试
测试1,写发生在主,2从分别可以读到刚才在主上发生的写


在主上我们插入一条记录(order_id自增长)

现在我们连上从1-192.168.2.102


再连上从2-192.168.2.103


完成1主2从的同步,下面我们进入haproxy的搭建
Haproxy的2机热备搭建
安装和配置haproxy
为了演练,我们把haproxy分别安装在和mysql2个slaver一起的主机上,真实生产要记得专门为haproxy安排2台额外的单独主机
yum -y install haproxy在mysql slaver上创建一个无权限用于haproxy与mysql间心跳检测用的mysql用户
create user 'haproxy' identified by '';因为前面我们为了演练方便,因此把每个mysql的password策略给禁了,如果是在生产环境这是不可能的,也就是说此处的 identified by '一定有密码',要不然以上这个sql是过不了的。那么没关系,创建完后我们用set password或者用mysql图形化客户端把这个密码给改成“空”吧,因为是无权限用户,因此一点不用担心。
Haproxy的log不会记录在磁盘上,便于我们今后监控和查看Haproxy的日志,我们这边需要把Haproxy的日志和centos的rsyslog作一个关联。
cd /var/log
mkdir haproxy
cd haproxy
touch haproxy.log
chmod a+w haproxy.log
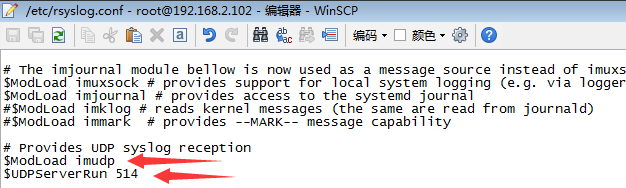
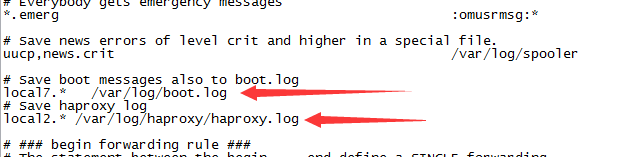
vim /etc/rsyslog.cnf --修改rsyslog.cfg文件把原文件中的以下两行放开:
# $ModLoad imudp
#$UDPServerRun 514
并增加以下3行
$ModLoad imudp
$UDPServerRun 514
#新增的行
local7.* /var/log/boot.log
# Save haproxy log
#新增的行
local2.* /var/log/haproxy/haproxy.log加完后完整的样子是这样的
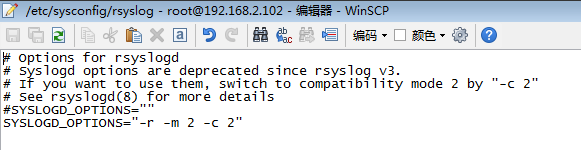
还没完,继续修改/etc/sysconfig/rsyslog
vim /etc/sysconfig/rsyslogSYSLOGD_OPTIONS="" 改为 SYSLOGD_OPTIONS="-r -m 2 -c 2"
改完后重启rsyslog
systemctl restart rsyslog开始编辑/etc/haproxy/haproxy.cfg文件
haproxy1-192.168.2.102上的配置
把文件内容整个替换成这样吧
global
# to have these messages end up in /var/log/haproxy.log you will
# need to:
#
# 1) configure syslog to accept network log events. This is done
# by adding the '-r' option to the SYSLOGD_OPTIONS in
# /etc/sysconfig/syslog
#
# 2) configure local2 events to go to the /var/log/haproxy.log
# file. A line like the following can be added to
# /etc/sysconfig/syslog
#
# local2.* /var/log/haproxy.log
#
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
# turn on stats unix socket
stats socket /var/lib/haproxy/stats
#---------------------------------------------------------------------
# common defaults that all the 'listen' and 'backend' sections will
# use if not designated in their block
#---------------------------------------------------------------------
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
option forwardfor except 127.0.0.0/8
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 5m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 2000
#---------------------------------------------------------------------
# main frontend which proxys to the backends
#---------------------------------------------------------------------
## 定义一个监控页面,监听在1080端口,并启用了验证机制
listen stats
mode http
bind 0.0.0.0:1080
stats enable
stats hide-version
stats uri /dbs
stats realm Haproxy\ Statistics
stats auth admin:admin
stats admin if TRUE
listen proxy-mysql 0.0.0.0:23306
mode tcp
balance roundrobin
option tcplog
option mysql-check user haproxy #在mysql中创建无任何权限用户haproxy,且无密码
server ymkMySqlSlaver1 192.168.2.102:3306 check weight 1 maxconn 300
server ymkMySqlSlaver2 192.168.2.103:3306 check weight 1 maxconn 300
option tcpka在此,我们做了这么几件事:
- 开启了一个1080的haproxy自带监控界面,它的地址为http://192.168.2.102:1080/dbs
- 使用23306端口来代理mysql端口对外暴露给应用用,如:spring boot的jdbc pool的应用
- 使用haproxy自带的mysql-check user mysql上用于监听监控的用户此处就是haproxy来探测mysql的可用性
2个haproxy上都做同样的配置,接下去在192.168.2.102和192.168.2.103都按照这个顺序来重启rsyslog与haproxy。
systemctl restart rsyslog
systemctl restart haproxy接下去,我们可以使用http://192.168.2.103:1080/dbs或者是192.168.2.102:1080,用户名密码都为admin来监控haproxy了。

并且我们可以用192.168.2.102:23306以及192.168.2.103:23306,直接通过haproxy同时连上2台mysql的slavers。此时,在应用通过haproxy连上2个slavers时,只有一个mysql“挂”了,应用是无感知的,它会在毫秒内被飘移到另一个可用的mysql slaver上,我们来做实验。
我们通过192.168.2.102:23306连上2个mysql的slaver


查询执行成功,然后我们来杀掉任意一台mysql。。。嗯。。。192.168.2.102,就杀了你吧,嗯,对,就是你!!!

好,我被杀了!

再次回到应用连接处,依旧执行一次查询

老婆,出来看上帝。。。看,查询依旧可以被执行,说明,Haproxy已经帮我们把应用连接自动飘到了192.168.2.103上去了。
再做个测试,我们来杀haproxy,杀192.168.2.103上的haproxy


看,应用连接依然有效,说明192.168.2.102上的haproxy起作用了。
接下去就是keepalived的布署了,激动人心的时候就要到来鸟!
布署keepAlived集群
安装KeepAlived
在每台slaver上安装keepalived,因为是演练环境,因此我们把keepalived也装在和haproxy一起的vm上,如果是生产环境一定记得要为keepalived布署单独的server,至少2台。
yum instlal keepalived简单的不能再简单了。
配置keepalived
注意了!每台keepalived的配置是不同的,这里分主次关系,这里不像keepalived是load roubin的概念,这可是有优先级的概念哦。
对/etc/keepalived/keepalived.conf文件进行编辑。
192.168.2.102上的keepalived-lb01
global_defs {
router_id LB01
}
vrrp_script chk_haproxy
{
script "/etc/keepalived/scripts/haproxy_check.sh"
interval 2
timeout 2
fall 3
}
vrrp_instance haproxy {
state MASTER
#interface eth0
interface enp0s3
virtual_router_id 1
priority 100
authentication {
auth_type PASS
auth_pass password
}
unicast_peer {
192.168.2.102
192.168.2.103
}
virtual_ipaddress {
192.168.2.201
}
track_script {
chk_haproxy
}
notify_master "/etc/keepalived/scripts/haproxy_master.sh"
}此处我们做了如下几件事:
- 设定了192.168.2.102为 master状态
- 名字为:LB01
- 优先级为100,当然,另一台keepalived的话一定优先级比他低,一定记得,从机的priority小于主机的priority
- 定义了一个虚拟ip,它叫192.168.2.201,有了这个ip后,一切应用都通过这个ip来访问mysql的slavers集群了
- 把该虚ip绑定到“interface enp0s3”网卡上,这块网卡是我在192.168.2.102上的千兆网络接口的系统接口名
192.168.2.103上的keepalived-lb02
此处,有2个地方和lb01的配置有不同:
- router_id
- priority
global_defs {
router_id LB02
}
vrrp_script chk_haproxy
{
script "/etc/keepalived/scripts/haproxy_check.sh"
interval 2
timeout 2
fall 3
}
vrrp_instance haproxy {
state BACKUP
#interface eth0
interface enp0s3
virtual_router_id 1
priority 50
authentication {
auth_type PASS
auth_pass password
}
unicast_peer {
192.168.2.102
192.168.2.103
}
virtual_ipaddress {
192.168.2.201
}
track_script {
chk_haproxy
}
notify_master "/etc/keepalived/scripts/haproxy_master.sh"
}下面给出haproxy_check.sh和haproxy_master.sh文件的内容
haproxy_check.sh-每个keepalived的机器上都要放
#!/bin/bash
LOGFILE="/var/log/keepalived-haproxy-state.log"
date >>$LOGFILE
if [ `ps -C haproxy --no-header |wc -l` -eq 0 ];then
echo "fail: check_haproxy status" >>$LOGFILE
exit 1
else
echo "success: check_haproxy status" >>$LOGFILE
exit 0
fihaproxy_master.sh-每个keepalived的机器上都要放
#!/bin/bash
LOGFILE="/var/log/keepalived-haproxy-state.log"
echo "Being Master ..." >> $LOGFILE
测试keepalived功能
先把两台机器上的keepalived启动起来

测试1:通过VIP:192.168.2.201:23306连入mysql


成功!
测试2:杀192.168.2.102上的mysql进程后并通过vip查询



飘移成功!!!
测试3:杀192.168.2.102上的haproxy进程后并通过vip查询


成功,毫无压力!!!Come on, again, I wanna more!
测试4:杀192.168.2.103上的haproxy,对mysql master作写,并在2从上做读
以观看keepalived对haproxy是否真正起到了热备

![]()



结论
keepalived+haproxy+mysql的1主多从的热备搭建成功!
下面我们来攻克另一个课题,那就是,如何在springboot应用中,不要让我们一群开发每个人记得“主写-从读”并在编码上自己去实现,我们需要在整体代码框架层统一去做“拦截”,以实现自动根据service层的方法名来做到 “主写-从读”。
代码层实现主写-从读的自动拦截封装解决方案
框架一览

pom.xml中需要额外加入的内容
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
</dependency>applicatin.properties
此处我们定义了2个数据源,一个叫master,一个叫slaver,而slaver的地址我们即没指向192.168.2.102也没指向192.168.2.103,而是指向了keepalived暴露的那个虚IP192.168.2.201:23306
logging.config=classpath:log4j2.xml
#master db
mysql.datasource.master.type=com.alibaba.druid.pool.DruidDataSource
mysql.datasource.master.driverClassName=com.mysql.jdbc.Driver
mysql.datasource.master.url=jdbc:mysql://192.168.2.101:3306/ecom?useUnicode=true&characterEncoding=utf-8&useSSL=false
mysql.datasource.master.username=ecom
mysql.datasource.master.password=111111
mysql.datasource.master.initialSize=50
mysql.datasource.master.minIdle=50
mysql.datasource.master.maxActive=100
mysql.datasource.master.maxWait=60000
mysql.datasource.master.timeBetweenEvictionRunsMillis=60000
mysql.datasource.master.minEvictableIdleTimeMillis=120000
mysql.datasource.master.validationQuery=SELECT'x'
mysql.datasource.master.testWhileIdle=true
mysql.datasource.master.testOnBorrow=false
mysql.datasource.master.testOnReturn=false
mysql.datasource.master.poolPreparedStatements=true
mysql.datasource.master.maxPoolPreparedStatementPerConnectionSize=20
#slaver db
mysql.datasource.slaver1.type=com.alibaba.druid.pool.DruidDataSource
mysql.datasource.slaver1.driverClassName=com.mysql.jdbc.Driver
mysql.datasource.slaver1.url=jdbc:mysql://192.168.2.201:23306/ecom?useUnicode=true&characterEncoding=utf-8&useSSL=false
mysql.datasource.slaver1.username=ecom
mysql.datasource.slaver1.password=111111
mysql.datasource.slaver1.initialSize=50
mysql.datasource.slaver1.minIdle=50
mysql.datasource.slaver1.maxActive=100
mysql.datasource.slaver1.maxWait=60000
mysql.datasource.slaver1.timeBetweenEvictionRunsMillis=60000
mysql.datasource.slaver1.minEvictableIdleTimeMillis=120000
mysql.datasource.slaver1.validationQuery=SELECT'x'
mysql.datasource.slaver1.testWhileIdle=true
mysql.datasource.slaver1.testOnBorrow=false
mysql.datasource.slaver1.testOnReturn=false
mysql.datasource.slaver1.poolPreparedStatements=true
mysql.datasource.slaver1.maxPoolPreparedStatementPerConnectionSize=20启文件MultiDSDemo.java
package org.sky.retail.demo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration;
import org.springframework.boot.web.servlet.ServletComponentScan;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.transaction.annotation.EnableTransactionManagement;
@ServletComponentScan
@EnableAutoConfiguration(exclude = { DataSourceAutoConfiguration.class })
@ComponentScan(basePackages = { "org.sky.retail.demo" })
@EnableTransactionManagement
public class MultiDSDemo {
public static void main(String[] args) {
SpringApplication.run(MultiDSDemo.class, args);
}
}自动装配用MultiDSConfig.java
package org.sky.retail.demo.config;
import java.util.HashMap;
import java.util.Map;
import javax.sql.DataSource;
import org.sky.retail.demo.util.db.DBTypeEnum;
import org.sky.retail.demo.util.db.MyRoutingDataSource;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import com.alibaba.druid.pool.DruidDataSource;
@Configuration
public class MultiDSConfig {
@Bean
@ConfigurationProperties(prefix = "mysql.datasource.master")
public DataSource masterDataSource() {
return new DruidDataSource();
}
@Bean
@ConfigurationProperties(prefix = "mysql.datasource.slaver1")
public DataSource slave1DataSource() {
return new DruidDataSource();
}
@Bean
public DataSource myRoutingDataSource(@Qualifier("masterDataSource") DataSource masterDataSource,
@Qualifier("slave1DataSource") DataSource slave1DataSource) {
Map<Object, Object> targetDataSources = new HashMap<>();
targetDataSources.put(DBTypeEnum.MASTER, masterDataSource);
targetDataSources.put(DBTypeEnum.SLAVE1, slave1DataSource);
// targetDataSources.put(DBTypeEnum.SLAVE2, slave2DataSource);
MyRoutingDataSource myRoutingDataSource = new MyRoutingDataSource();
myRoutingDataSource.setDefaultTargetDataSource(masterDataSource);
myRoutingDataSource.setTargetDataSources(targetDataSources);
return myRoutingDataSource;
}
@Bean
public JdbcTemplate dataSource(DataSource myRoutingDataSource) {
return new JdbcTemplate(myRoutingDataSource);
}
@Bean
public DataSourceTransactionManager txManager(DataSource myRoutingDataSource) {
return new DataSourceTransactionManager(myRoutingDataSource);
}
}用于对service层方 法做自动切面实现“主写从读”的DataSourceAop.java
package org.sky.retail.demo.aop;
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.sky.retail.demo.util.db.DBContextHolder;
import org.springframework.stereotype.Component;
import org.springframework.web.context.request.RequestContextHolder;
import org.springframework.web.context.request.ServletRequestAttributes;
import javax.servlet.http.HttpServletRequest;
@Aspect
@Component
public class DataSourceAop {
protected Logger logger = LogManager.getLogger(this.getClass());
/**
* 定义切入点,切入点为org.sky.retail.demo.service下的所有函数
*/
@Pointcut("!@annotation(org.sky.retail.demo.util.db.Master) "
+ "&& (execution(* org.sky.retail.demo.service..*.select*(..)) "
+ "|| execution(* org.sky.retail.demo.service..*.get*(..)))")
public void readPointcut() {
}
@Pointcut("@annotation(org.sky.retail.demo.util.db.Master) "
+ "|| execution(* org.sky.retail.demo.service..*.insert*(..)) "
+ "|| execution(* org.sky.retail.demo.service..*.add*(..)) "
+ "|| execution(* org.sky.retail.demo.service..*.update*(..)) "
+ "|| execution(* org.sky.retail.demo.service..*.edit*(..)) "
+ "|| execution(* org.sky.retail.demo.service..*.delete*(..)) "
+ "|| execution(* org.sky.retail.demo.service..*.remove*(..))")
public void writePointcut() {
}
@Before("readPointcut()")
public void read(JoinPoint joinPoint) {
// 接收到请求,记录请求内容
ServletRequestAttributes attributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
HttpServletRequest request = attributes.getRequest();
DBContextHolder.slave();
}
@Before("writePointcut()")
public void write() {
DBContextHolder.master();
}DBTypeEnum.java
package org.sky.retail.demo.util.db;
public enum DBTypeEnum {
MASTER, SLAVE1;
}Master.java
package org.sky.retail.demo.util.db;
public @interface Master {
}用于实现多数据源路由的MyRoutingDataSource.java
package org.sky.retail.demo.util.db;
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
/**
* Created by mk on 2018/4/3 - to replace ODY's jdbc package.
*/
public class MyRoutingDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
return DBContextHolder.get();
}
}
MyRoutingDataSource.javaDBContextHolder.java
package org.sky.retail.demo.util.db;
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
import java.util.concurrent.atomic.AtomicInteger;
public class DBContextHolder {
protected static Logger logger = LogManager.getLogger(DBContextHolder.class);
private static final ThreadLocal<DBTypeEnum> contextHolder = new ThreadLocal<>();
private static final AtomicInteger counter = new AtomicInteger(0);
public static void set(DBTypeEnum dbType) {
contextHolder.set(dbType);
}
public static DBTypeEnum get() {
return contextHolder.get();
}
public static void master() {
set(DBTypeEnum.MASTER);
logger.info(">>>>>>切换到master");
}
public static void slave() {
set(DBTypeEnum.SLAVE1);
logger.info(">>>>>>切换到slave");
// 轮询用来实现应用程序随机飘移,下面这段代码如果说AZURE的PAAS上不能使用haproxy来飘那就只能使用原子类型取模来随机飘移多slaver了
// int index = counter.getAndIncrement() % 2;
// logger.info("counter.getAndIncrement() % 2======" + index);
// if (counter.get() > 9999) {
// counter.set(-1);
// }
// if (index == 0) {
// set(DBTypeEnum.SLAVE1);
// logger.info(">>>>>>切换到slave1");
// } else {
// set(DBTypeEnum.SLAVE1);// todo SLAVE2
// logger.info(">>>>>>切换到slave2");
// }
}
}Service类-OrderService.java
package org.sky.retail.demo.service;
import org.sky.retail.demo.vo.Order;
public interface OrderService {
public void insertOrder(Order order) throws Exception;
public Order getOrderByPK(int orderId) throws Exception;
}测试用-OrderController.java
package org.sky.retail.demo.controller;
import java.util.HashMap;
import java.util.Map;
import javax.annotation.Resource;
import org.sky.platform.retail.controller.BaseController;
import org.sky.retail.demo.service.OrderService;
import org.sky.retail.demo.vo.Order;
import org.springframework.http.HttpHeaders;
import org.springframework.http.HttpStatus;
import org.springframework.http.MediaType;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import io.swagger.annotations.ApiImplicitParam;
import io.swagger.annotations.ApiOperation;
import io.swagger.annotations.ApiResponses;
import io.swagger.annotations.ApiResponse;
@RestController
@RequestMapping("/demo/order")
public class OrderController extends BaseController {
@Resource
private OrderService orderService;
@ApiOperation(value = "创建一条订单", notes = "传入一个订单信息以增加一条订单")
@ApiResponses(value = { @ApiResponse(code = 200, message = "创建订单成功"),
@ApiResponse(code = 403, message = "创建订单失败,不能创建空的订单对象"),
@ApiResponse(code = 417, message = "创建订单失败, 因为某个系统错误") })
@RequestMapping(value = "/addEmployee", method = RequestMethod.POST)
public ResponseEntity<String> addOrder(@RequestBody String params) throws Exception {
ResponseEntity<String> response = null;
String returnResultStr;
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON_UTF8);
Map<String, Object> result = new HashMap<>();
try {
JSONObject requestJsonObj = JSON.parseObject(params);
if (requestJsonObj != null) {
Order order = getOrderFromJson(requestJsonObj);
logger.info(">>>>>>addOrder");
orderService.insertOrder(order);
result.put("code", HttpStatus.OK.value());
result.put("message", "insert a new order successfully");
result.put("orderId", order.getOrderId());
result.put("goodsId", order.getGoodsId());
result.put("amount", order.getAmount());
returnResultStr = JSON.toJSONString(result);
response = new ResponseEntity<>(returnResultStr, headers, HttpStatus.OK);
} else {
result.put("code", HttpStatus.FORBIDDEN.value());
result.put("message", "can not add a empty order");
}
} catch (Exception e) {
logger.error("addOrder error: " + e.getMessage(), e);
result.put("message", "add order error error: " + e.getMessage());
returnResultStr = JSON.toJSONString(result);
response = new ResponseEntity<>(returnResultStr, headers, HttpStatus.EXPECTATION_FAILED);
}
return response;
}
@ApiOperation(value = "通过订单ID获取订单信息接口", notes = "传入订单ID获取信息")
@ApiImplicitParam(name = "orderId", value = "订单ID", paramType = "query", defaultValue = "", required = true)
@RequestMapping(value = "/getOrderById", method = RequestMethod.GET)
public Order getOrderById(int orderId) throws Exception {
Order order = new Order();
try {
order = orderService.getOrderByPK(orderId);
} catch (Exception e) {
logger.error("getOrderById orderId->" + orderId + " error: " + e.getMessage(), e);
}
return order;
}
private Order getOrderFromJson(JSONObject requestObj) {
// int orderId = requestObj.getInteger("orderId");
int goodsId = requestObj.getInteger("goodsId");
int amount = requestObj.getInteger("amount");
Order order = new Order();
// order.setOrderId(orderId);
order.setGoodsId(goodsId);
order.setAmount(amount);
return order;
}
}测试
测试1-写Go Master读Go Slaver
读操作测试
为了测试可视化,我有意在DbContextHolder处做了2个日志输出。






测试2-杀192.168.2.102上的mysql来进行读


无任何压力,毫秒级飘移!
测试3-杀192.168.2.103上的keeyalived来进行读-这个有点猛
猛也要杀啊,程序员没啥难的,JAVA从入门到删库跑路,PYTHON零基础到进精神病院!


毫无压力,看到没!
测试4-别测了你,再测用jmeter去吧,打完收工!
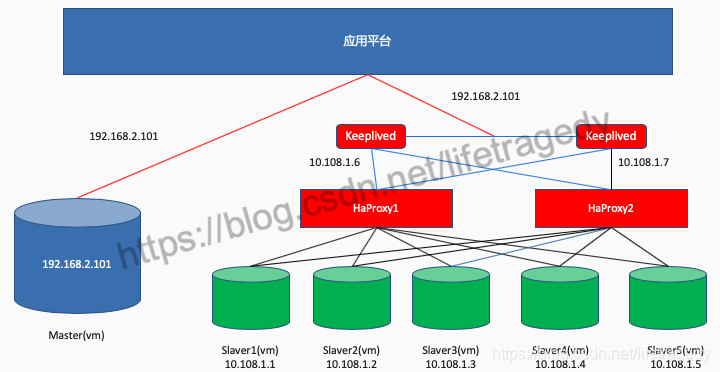
想收工?可能吗?附一张生产级别haproxy+keepalived的布署图
一定记得:
- haproxy实际生产要和mysql分开布。
- haproxy+keepalived可以在一个vm上。
前面如果是在腾讯或者是ali云用lvs做vip地址转换,如果是azure就用ILB把vip转向应用层。
