机器学习算法1---KNN
目录
一、KNN算法原理
1、KNN三要素
2、一个简单案例
3、算法原理简单实现
【KNN分类---等权】
【KNN分类-加权】
【KNN回归---等权】
【KNN回归---加权】
4、注意要点
二、KNN算法实现
1、参数说明
2、鸢尾花数据案例
3、算法特点
一、KNN算法原理
k近邻(k-nearst-neiber),它计算的是待预测样本属性和标签样本属性的距离, 每个样本都可以用它最接近的k个邻居来代表。
它是监督学习,做分类&回归任务都可以。KNN在分类预测时,一般采用多数表决法;而在做回归预测时,一般采用平均值法。
1、KNN三要素
1)、【计算距离】计算待预测样本与训练集样本的距离
2)、【确定K值】从训练集中获取K个离待预测样本距离最近的样本数据
3)、【决策规则】K个中哪类样本多,这个待预测样本就判断为哪类
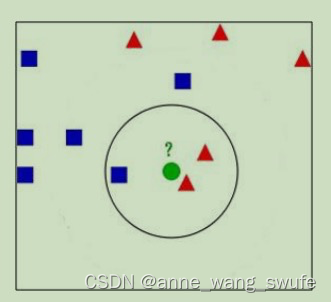
多数表决原则在计算机中有着广泛应用,特别是在自组织结构,也就是缺乏中心结构的体系中。区块链技术中发挥了核心作用的共识计算实质上也是遵照了多数表决原则。
2、一个简单案例

1)、【计算距离】将训练集中所有样例画入坐标系,计算待预测电影与已知分类的电影的欧式距离。
2)、【确定K值】按照距离升序排序,取前K个电影,假设k=3
3)、【决策规则】K个中哪类样本多,这个待预测电影就判断为哪类
3、算法原理简单实现
【距离】一般是欧式距离
python计算欧式距离的3种方法:
a1 =np.array([3,104])
a2 =np.array([18,90])
dis1 = np.sum((np.array(a1) - np.array(a2)) ** 2) ** 0.5
dis2 = np.sqrt(np.sum(np.square(a1-a2)))
dis3 =np.linalg.norm(a1-a2)
# print(dis1) #20.518284528683193
# print(dis2) #20.518284528683193
# print(dis3) #20.518284528683193【K值】K值太小,容易过拟合;K值太大容易欠拟合;因此需要网格搜索调参
【决策规则】分类模型(多数表决或加权多数表决),回归模型(平均值法或者加权平均值法)
加权---越近的投票权越大,通常用距离反比。
(1)多数表决和加权多数表决案例:
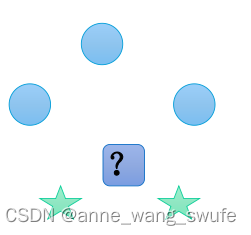
案例:距离待预测样本最近的5个点里,A类3个(距离分别是2,2,2),B类2个(距离分别是1,1)
- 多数表决:A类3票,B类2票,判为A类;
- 加权多数表决:
1)距离权重,A类(1/2票+1/2票+1/2票),B类(1票+1票)
2)距离权重和,sum=1/2+1/2+1/2+1+1=7/2
3)距离权重归一化,A1=(1/2)/ sum=1/7票 ;B1=(1)/sum =2/7票
4)分类求和:A类3/7票,B类4/7票,判为B类。
【KNN分类---等权】
##一、等权分类
import numpy as np
import pandas as pd
##初始化训练数据
T = [[3, 104, -1],
[2, 100, -1],
[1, 81, -1],
[101, 10, 1],
[99, 5, 1],
[98, 2, 1]
]
##预测数据
x_test = [18, 90]
##邻居
K = 5
##思路:
#1、计算x到所有样本点的距离---sqrt((x1-x2)^2+(y1-y2)^2)
#2、距离从低到高排序,选前5个
#3、看5个样本点中-1和1的类别数量,谁的数量多判断为哪一类
"""1、计算x到所有样本点的距离---sqrt((x1-x2)^2+(y1-y2)^2)"""
listdistance = []
for t in T: ## t是每条电影的数据
dis = np.sum((np.array(t[:-1]) - np.array(x_test)) ** 2) ** 0.5
listdistance.append([dis, t[-1]])
# print(listdistance)
# [[20.518284528683193, -1],
# [18.867962264113206, -1],
# [19.235384061671343, -1],
# [115.27792503337315, 1],
# [117.41379816699569, 1],
# [118.92854997854805, 1]]
"""2、距离从低到高排序,选前5个"""
##按照dis进行排序
listdistance.sort()
# print(listdistance)
# [[18.867962264113206, -1],
# [19.235384061671343, -1],
# [20.518284528683193, -1],
# [115.27792503337315, 1],
# [117.41379816699569, 1],
# [118.92854997854805, 1]]
listdistance=listdistance[:K]
"""3、看5个样本点中-1和1的类别数量,谁的数量多判断为哪一类"""
##选取K个邻居放入投票箱
arr = np.array(listdistance[:K])[:, -1] #所有行,最后一列,降维
# print(arr)
# [-1. -1. -1. 1. 1.]
##统计投票
# 方法1:转成Series,使用value_counts()
a = pd.Series(arr).value_counts() #转换成Series格式
# print(a)
# # -1.0 3
# # 1.0 2
pre = a.idxmax()
# print(pre) #-1.0
##方法2: 转成DataFrame
df = pd.DataFrame(arr)[0].value_counts() #转成DataFrame,要制定某一列才能使用该函数
print(df)
# -1.0 3
# 1.0 2
pre1 = df.idxmax()
print(pre1)
# -1.0
【KNN分类-加权】
import pandas as pd
import numpy as np
##初始化训练数据
T = [[3, 104, -1],
[2, 100, -1],
[1, 81, -1],
[101, 10, 1],
[99, 5, 1],
[98, 2, 1]
]
##预测数据
x_test = [18, 90]
##邻居
K = 5
##思路:
#1、计算x到所有样本点的距离---sqrt((x1-x2)^2+(y1-y2)^2)
#2、距离从低到高排序,选前5个
#3、计算权重,权重=1/距离,标准化权重票数=(1/每个点距离)/sum()
#4、那一类的权重票数多就归为哪类
"""1、计算x到所有样本点的距离---sqrt((x1-x2)^2+(y1-y2)^2)"""
dis_list=[]
for t in T:
distence = np.sqrt(sum((np.array(t[:-1])-np.array(x_test))**2))
dis_list.append([distence,t[-1]])
# print(dis_list)
# # [[20.518284528683193, -1],
# # [18.867962264113206, -1],
# # [19.235384061671343, -1],
# # [115.27792503337315, 1],
# # [117.41379816699569, 1],
# # [118.92854997854805, 1]]
"""2、距离从低到高排序,选前5个"""
# dis_sort_k = pd.DataFrame(np.array(dis_list),columns=['score', 'y']).sort_values(by='score',ascending=True).head(K)
# print(dis_sort_k)
# score y
# 1 18.867962 -1.0
# 2 19.235384 -1.0
# 0 20.518285 -1.0
# 3 115.277925 1.0
# 4 117.413798 1.0
"""3、计算权重,权重=1/距离,标准化权重=(1/每个点距离)/sum(),加权票数=标准化权重"""
# dis_sort_k['weight']=dis_sort_k['score'].apply(lambda x: 1/(x+0.0001))
# sum_weight = dis_sort_k['weight'].sum()
# dis_sort_k['weight_score'] = dis_sort_k['weight']/sum_weight
# print(dis_sort_k)
# score y weight weight_score
# 1 18.867962 -1.0 0.053000 0.310093
# 2 19.235384 -1.0 0.051987 0.304170
# 0 20.518285 -1.0 0.048737 0.285152
# 3 115.277925 1.0 0.008675 0.050754
# 4 117.413798 1.0 0.008517 0.049831
"""4、那一类的权重票数多就归为哪类"""
# result = dis_sort_k.groupby('y')['weight_score'].sum()
# # print(result)
# # y
# # -1.0 0.899415
# # 1.0 0.100585
# pre = result.idxmax() #取最大值的索引
# print(pre) #-1
(2)平均值法或者加权平均值法
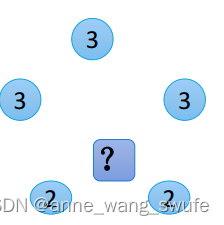
距离待预测样本最近的5个点里,A类3个(距离分别是2,2,2;y值分别是3,3,3),B类2个(距离分别是1,1;y值分别是2,2)
平均值法:(3+3+3+3+2)/5 = 2.6 ---5个y值的平均
加权平均值法:
1)距离权重:A类3个点距离权重(1/2,1/2,1/2),B类2个点距离权重(1,1)
2)权重和,sum=1/2+1/2+1/2+1+1=7/2
3)权重归一化,A1=(1/2) / sum=1/7 ;B1=(1)/ sum =2/7
4)求和:1/7*3+1/7*3+1/7*3 + 2/7*2+ 2/7 *2 =2.43 ---权重*y值
【KNN回归---等权】
# ## KNN等权--回归
import numpy as np
# #初始化数据
T = [
[3, 104, 98],
[2, 100, 93],
[1, 81, 95],
[101, 10, 16],
[99, 5, 8],
[98, 2, 7]]
# #初始化待测样本
x_test = [18, 90]
# #初始化邻居数
K = 5
##思路:
#1、计算x到所有样本点的距离---sqrt((x1-x2)^2+(y1-y2)^2)
#2、距离从低到高排序,选前5个
#3、取前5个的y值求平均值,则为预测值
"""1、计算x到所有样本点的距离---sqrt((x1-x2)^2+(y1-y2)^2)"""
listdistance = []
for t in T: ## t是每条电影的数据
dis = np.sum((np.array(t[:-1]) - np.array(x_test)) ** 2) ** 0.5
listdistance.append([dis, t[-1]])
# print(listdistance)
# [[20.518284528683193, 98],
# [18.867962264113206, 93],
# [19.235384061671343, 95],
# [115.27792503337315, 16],
# [117.41379816699569, 8],
# [118.92854997854805, 7]]
"""2、距离从低到高排序,选前5个"""
##按照dis进行排序
listdistance.sort()
# print(listdistance)
# [[18.867962264113206, 93],
# [19.235384061671343, 95],
# [20.518284528683193, 98],
# [115.27792503337315, 16],
# [117.41379816699569, 8],
# [118.92854997854805, 7]]
"""3、取前5个的y值求平均值,则为预测值"""
pre = np.mean(np.array(listdistance[:K])[:, -1])
print(pre)
# 62.0
【KNN回归---加权】
# # KNN加权回归
import pandas as pd
import numpy as np
# #初始化数据
T = [
[3, 104, 98],
[2, 100, 93],
[1, 81, 95],
[101, 10, 16],
[99, 5, 8],
[98, 2, 7]]
# #初始化待测样本
x_test = [18, 90]
# #初始化邻居数
K = 5
##思路:
#1、计算x到所有样本点的距离---sqrt((x1-x2)^2+(y1-y2)^2)
#2、距离从低到高排序,选前5个
#3、计算权重,权重=1/距离,标准化权重=权重/sum(权重)
#4、前5个点sum(标准化权重*y值)---即为预测值
"""1、计算x到所有样本点的距离---sqrt((x1-x2)^2+(y1-y2)^2)"""
dis_list=[]
for t in T:
distence = np.sqrt(sum((np.array(t[:-1])-np.array(x_test))**2))
dis_list.append([distence,t[-1]])
# print(dis_list)
# [[20.518284528683193, 98],
# [18.867962264113206, 93],
# [19.235384061671343, 95],
# [115.27792503337315, 16],
# [117.41379816699569, 8],
# [118.92854997854805, 7]]
"""2、距离从低到高排序,选前5个"""
dis_sort_k = pd.DataFrame(np.array(dis_list),columns=['score', 'y']).sort_values(by='score',ascending=True).head(K)
# print(dis_sort_k)
# score y
# 1 18.867962 93.0
# 2 19.235384 95.0
# 0 20.518285 98.0
# 3 115.277925 16.0
# 4 117.413798 8.0
"""3、计算权重,权重=1/距离,标准化权重=权重/sum(权重)"""
dis_sort_k['weight']=dis_sort_k['score'].apply(lambda x: 1/(x+0.0001))
sum_weight = dis_sort_k['weight'].sum()
dis_sort_k['weight_score'] = dis_sort_k['weight']/sum_weight
# print(dis_sort_k)
# score y weight weight_score
# 1 18.867962 93.0 0.053000 0.310093
# 2 19.235384 95.0 0.051987 0.304170
# 0 20.518285 98.0 0.048737 0.285152
# 3 115.277925 16.0 0.008675 0.050754
# 4 117.413798 8.0 0.008517 0.049831
"""4、前5个点sum(标准化权重*y值)---即为预测值"""
dis_sort_k['y_weight_score']=dis_sort_k['y']*dis_sort_k['weight_score']
print(dis_sort_k['y_weight_score'].sum())
# 86.89041337014999
4、注意要点
(1)思考--KNN需要特征标准化吗?
需要,特征标准化是为了去除量纲,因为KNN算法要计算距离,距离会受量纲的影响
(2)思考---算法实现方式有什么需要改进的?
蛮力实现---计算预测样本到所有训练集样本的距离,然后选择最小的k个距离即可得到K个最邻近点。缺点在于当特征数比较多、样本数比较多的时候,算法的执行效率比较低;于是有了KD树的查找样本的方式
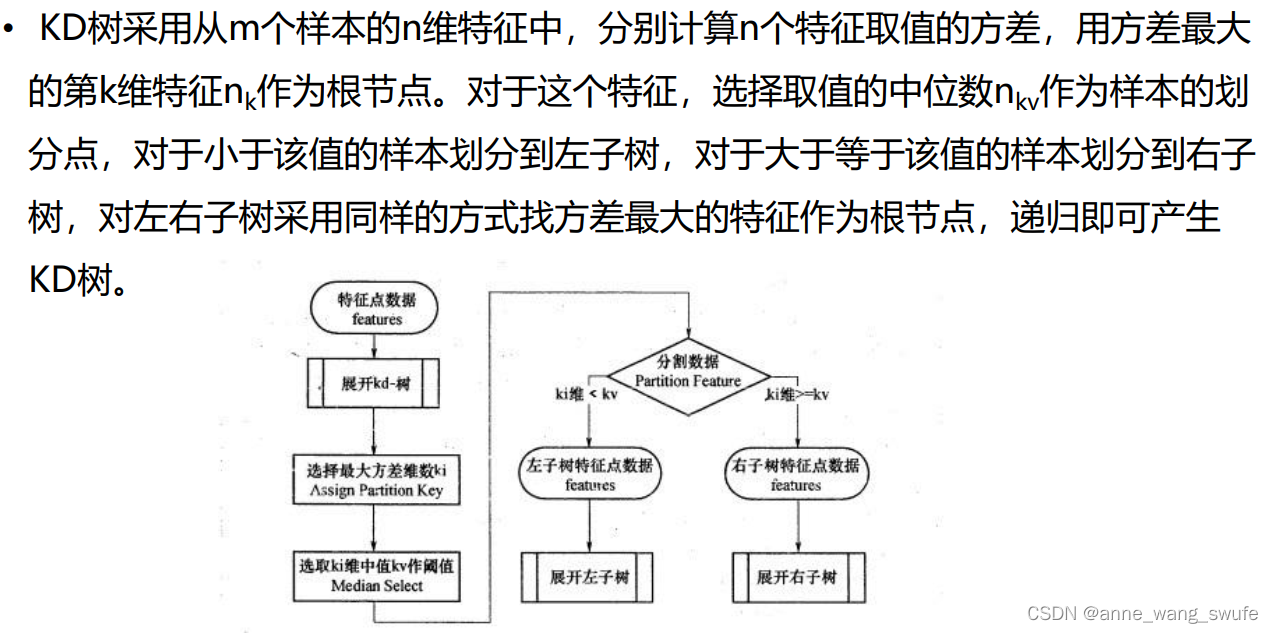
详细过程见:
KNN算法和kd树详解(例子+图示)_zzpzm的博客-CSDN博客_knn和kd树
KDtree跟构建二分查找法一样,方差大的那一列切割后,方差减少的比较多。
KDtree找点很快,实现快速检索功能;不仅可以用在KNN里;比如现在做一个人脸识别,假设有100000人,也可以用KDtree思想。
二、KNN算法实现
1、参数说明

【KNN分类】
class sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, *, weights='uniform', algorithm='auto', leaf_size=30, p=2, metric='minkowski', metric_params=None, n_jobs=None)
sklearn.neighbors.KNeighborsClassifier — scikit-learn 1.1.2 documentation
【KNN回归】
class sklearn.neighbors.KNeighborsRegressor(n_neighbors=5, *, weights='uniform', algorithm='auto', leaf_size=30, p=2, metric='minkowski', metric_params=None, n_jobs=None)
sklearn.neighbors.KNeighborsRegressor — scikit-learn 1.1.2 documentation
2、鸢尾花数据案例
import pandas as pd
import numpy as np
import sys
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import GridSearchCV
"""1、数据加载"""
path = "../datas/iris.data"
names = ['A', 'B', 'C', 'D', 'cla']
df = pd.read_csv(filepath_or_buffer=path, sep=",", header=None, names=names)
# print(df.head())
# A B C D cla
# 0 5.1 3.5 1.4 0.2 Iris-setosa
# 1 4.9 3.0 1.4 0.2 Iris-setosa
# 2 4.7 3.2 1.3 0.2 Iris-setosa
# 3 4.6 3.1 1.5 0.2 Iris-setosa
# 4 5.0 3.6 1.4 0.2 Iris-setosa
"""2、数据清洗"""
"""#(1) 熟悉数据"""
# print(df.info()) #1)查看字段类型和缺失情况
# 0 A 150 non-null float64
# 1 B 150 non-null float64
# 2 C 150 non-null float64
# 3 D 150 non-null float64
# 4 cla 150 non-null object
# print(df.describe()) #2)查看分布情况-数值数据
# A B C D
# count 150.000000 150.000000 150.000000 150.000000
# mean 5.843333 3.054000 3.758667 1.198667
# std 0.828066 0.433594 1.764420 0.763161
# min 4.300000 2.000000 1.000000 0.100000
# 25% 5.100000 2.800000 1.600000 0.300000
# 50% 5.800000 3.000000 4.350000 1.300000
# 75% 6.400000 3.300000 5.100000 1.800000
# max 7.900000 4.400000 6.900000 2.500000
# print(df.describe(include=[np.object])) #3)查看分布情况-分类数据
# cla
# count 150
# unique 3
# top Iris-setosa
# freq 50
# print(df['cla'].value_counts()) #4)查看某列分类数据的唯一值和数量
# Iris-setosa 50
# Iris-versicolor 50
# Iris-virginica 50
# Name: cla, dtype: int64
"""#(5) 数据类型变换&新增字段"""
#Y值是字符串,要转换成0,1,2
def func_y(y):
if y=='Iris-setosa':
return 0
elif y=='Iris-versicolor':
return 1
else:
return 2
df['cla2']=df['cla'].map(lambda y : func_y(y))
# print(df['cla2'].value_counts())
# 0 50
# 1 50
# 2 50
# Name: cla2, dtype: int64
"""3、获取我们的数据的特征属性X和目标属性Y"""
X =df[['A','B','C','D']].values #注意这里要转化成numpy形式,df记得取values
Y = df['cla2'].values
"""4、数据分割【指的是把数据划分为训练集和测试集】"""
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.25, random_state=5)
"""5、特征工程 正则化、标准化,编码"""
"""(2)标准化"""
ss = StandardScaler(with_mean=True, with_std=True)
x_train = ss.fit_transform(x_train)
x_test = ss.transform(x_test)
"""6、构建和训练模型"""
# 语法:
# #(1)参数调优
# 1)构建模型:模型实例名A = 模型类()
# 2)参数范围:param_grid=[{}]
# 3) 网格搜索:调优模型实例名estimator = GridSearchCV(模型实例名A, param_grid, cv=5, scoring='accuracy')
# 3)用调优模型进行训练:调优模型实例名estimator.fit(x_train, y_train)
##(2) 查看最优参数
# print("交叉验证中验证的最好结果",estimator.best_score_)
# print("最好的参数模型",estimator.best_estimator_)
# print("最好的参数",estimator.best_params_)
##(3)用最优参数建模
KNN = KNeighborsClassifier()
param_grid = [
{
'weights':['uniform','distance'],
'algorithm' :['auto','kd_tree','ball_tree'],
'n_neighbors':[i for i in range(3, 20,2)], #3-19
'p':[1,2] #距离参数
}
]
estimator = GridSearchCV(KNN, param_grid, cv=10, scoring='accuracy')
estimator.fit(x_train, y_train)
# 查看交叉验证和网络搜索的结果
print("交叉验证中验证的最好结果",estimator.best_score_) #0.9727272727272727
print("最好的参数模型",estimator.best_estimator_)
# KNeighborsClassifier(n_neighbors=9, weights='distance')
print("最好的参数",estimator.best_params_)
# {'algorithm': 'auto', 'n_neighbors': 9, 'p': 2, 'weights': 'distance'}
"""7、模型效果的评估 (效果不好,返回第二步进行优化,达到要求)"""
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score,roc_auc_score
score = estimator.score(x_test,y_test)
print("准确率为:",score) #0.9473684210526315
y_train_hat = estimator.best_estimator_.predict(x_train) #训练集predict
yPredict = estimator.best_estimator_.predict(x_test) #测试集predict
train_accuracy_score = accuracy_score(y_train,y_train_hat)
test_accuracy_score = accuracy_score(y_test,yPredict)
# print(train_accuracy_score) 1.0
# print(test_accuracy_score) 0.9473684210526315
3、算法特点
KNN是一种非参的、惰性的算法模型。什么是非参,什么是惰性呢?
非参的意思并不是说这个算法不需要参数,而是意味着这个模型不会对数据做出任何的假设,与之相对的是线性回归(我们总会假设线性回归是一条直线)。也就是说 KNN 建立的模型结构是根据数据来决定的,这也比较符合现实的情况,毕竟在现实中的情况往往与理论上的假设是不相符的。
惰性又是什么意思呢?想想看,同样是分类算法,逻辑回归需要先对数据进行大量训练(tranning),最后才会得到一个算法模型。而 KNN 算法却不需要,它没有明确的训练数据的过程,或者说这个过程很快。