Flink(二)
目录
三:Flink 部署
3.1.1 Flink部署
3.1.2 向集群提交作业
3.2 部署模式
3.2.1 会话模式(Session Mode)
3.2.2 单作业模式( Per-Job Mode)
3.2.3 应用模式(Application Mode)
3.3 独立模式(Standalone)
3.3.1 会话模式部署
3.3.2 单作业模式部署
3.3.3 应用模式部署
3.4 YARN 模式
3.4.1 相关准备和配置
3.4.2 会话模式部署
3.4.3 单作业模式部署
3.4.4 应用模式部署
三:Flink 部署
3.1.1 Flink部署
Flink集群中的主要组件。

这里就直接开始部署集群Flink,而不是单节点的本地部署了。

上面就是部署情况了,接下来安装Flink。
1 . 下载安装包
进入 Flink 官网,下载 1.13.0 版本安装包 flink-1.13.0-bin-scala_2.12.tgz,注意此处选用对 应 scala 版本为 scala 2.12 的安装包。
2. 解压
在 hadoop102 节点服务器上创建安装目录/opt/module,将 flink 安装包放在该目录下,并 执行解压命令,解压至当前目录。
3. 修改集群配置
( 1)进入 conf 目录下,修改 flink-conf.yaml 文件,修改 jobmanager.rpc.address 参数为
hadoop102,如下所示:
$ cd conf/
$ vim flink-conf . yaml # JobManager 节点地址 . j obmanager . rpc . addres s : hadoop1 02这就指定了 hadoop102 节点服务器为 JobManager 节点。
(2)修改 workers 文件,将另外两台节点服务器添加为本 Flink 集群的 TaskManager 节点, 具体修改如下:
$ vim workers hadoop1 0 3 hadoop1 0 4这样就指定了 hadoop103 和 hadoop104 为 TaskManager 节点。
(3)另外,在 flink-conf.yaml 文件中还可以对集群中的 JobManager 和 TaskManager 组件 进行优化配置,主要配置项如下:
⚫ jobmanager.memory.process.size:对 JobManager 进程可使用到的全部内存进行配置, 包括 JVM 元空间和其他开销,默认为 1600M,可以根据集群规模进行适当调整。
⚫ taskmanager.memory.process.size:对 TaskManager 进程可使用到的全部内存进行配置, 包括 JVM 元空间和其他开销,默认为 1600M,可以根据集群规模进行适当调整。
⚫ taskmanager.numberOfTaskSlots:对每个 TaskManager 能够分配的 Slot 数量进行配置, 默认为 1,可根据 TaskManager 所在的机器能够提供给 Flink 的 CPU 数量决定。所谓
Slot 就是 TaskManager 中具体运行一个任务所分配的计算资源。
⚫ parallelism.default: Flink 任务执行的默认并行度,优先级低于代码中进行的并行度配 置和任务提交时使用参数指定的并行度数量。
关于 Slot 和并行度的概念,我们会在下一章做详细讲解。
4. 分发安装目录
配置修改完毕后,将 Flink 安装目录发给另外两个节点服务器。
$ scp -r . / flink- 1 . 1 3 . 0 atguigu@hadoop1 0 3 : /opt/module $ scp -r . / flink- 1 . 1 3 . 0 atguigu@hadoop1 0 4 : /opt/module5. 启动集群
( 1)在 hadoop102 节点服务器上执行 start-cluster.sh 启动 Flink 集群:
$ bin/ start-cluster . sh Starting cluster . Starting standaloneses sion daemon on host hadoop1 02 . Starting taskexecutor daemon on host hadoop1 0 3 . Starting taskexecutor daemon on host hadoop1 0 4 .(2)查看进程情况:
[ atguigu@hadoop1 02 flink- 1 . 1 3 . 0 ] $ j ps 1 3 8 5 9 Jps 1 3 7 82 StandaloneSes sionClusterEntrypoint [ atguigu@hadoop1 0 3 flink- 1 . 1 3 . 0 ] $ j ps 12 2 1 5 Jps
12 12 4 TaskManagerRunner [ atguigu@hadoop1 0 4 flink- 1 . 1 3 . 0 ] $ j ps 1 1 602 TaskManagerRunner 1 1 6 94 Jps6. 访问 Web UI
启动成功后,同样可以访问 http://hadoop102:8081 对 flink 集群和任务进行监控管理

3.1.2 向集群提交作业
1 . 程序打包
( 1)为方便自定义结构和定制依赖,我们可以引入插件 maven-assembly-plugin 进行打包。 在 FlinkTutorial 项目的 pom.xml 文件中添加打包插件的配置
向pom.xml文件中添加如下代码
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>(2)插件配置完毕后,可以使用 IDEA 的 Maven 工具执行 package 命令,出现如下提示即 表示打包成功。 
打 包 完 成 后 , 在 target 目 录 下 即 可 找 到 所 需 JAR 包 , JAR 包 会 有 两 个 ,
FlinkTutorial-1.0-SNAPSHOT.jar 和 FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar,因 为集群中已经具备任务运行所需的所有依赖,所以建议使用 FlinkTutorial-1.0-SNAPSHOT.jar。
2. 在 Web UI 上提交作业
( 1)任务打包完成后,我们打开 Flink 的 WEB UI 页面,在右侧导航栏点击“ Submit New Job”,然后点击按钮“+ Add New”,选择要上传运行的 JAR 包

(2)上传jar包

(3)点击该 JAR 包,出现任务配置页面,进行相应配置。
主要配置程序入口主类的全类名,任务运行的并行度,任务运行所需的配置参数和保存点 路径等,如图 3-6 所示,配置完成后,即可点击按钮“ Submit”,将任务提交到集群运行。

(4)任务提交成功之后,可点击左侧导航栏的“Running Jobs”查看程序运行列表情况

(5)点击该任务,可以查看任务运行的具体情况,也可以通过点击“Cancel Job”结束任务运行

附:
用命令行在Flink集群提交任务
首先,现在hadoop102中输入
nc -lk 7777
然后,在hadoop103中,先导入要执行的任务的jar包,然后执行如下命令
./bin/flink run -m hadoop102:8081 -c com.atguigu.wc.StreamWordCount -p 2 ./FlinkTuorial-1.0-SNAPSHOT.jar
这样,就可以成功提交命令了。
这里说明一下上面命令的参数:
-m:传入数据源的主机名
-c:传入要执行任务的引用全名
-p:传入并行度的大小
最后,如果任务已经执行完了,可以停止了,在hadoop103中执行如下命令
[axing@hadoop103 flink-1.13.0]$ ./bin/flink cancel dba8e880c1cdc03442c735115231ae35
说明:后面接的是任务的id。
3.2 部署模式
在一些应用场景中,对于集群资源分配和占用的方式,可能会有特定的需求。Flink 为各种场景提供了不同的部署模式,主要有以下三种:⚫ 会话模式(Session Mode)⚫ 单作业模式(Per-Job Mode)⚫ 应用模式(Application Mode)
3.2.1 会话模式(Session Mode)
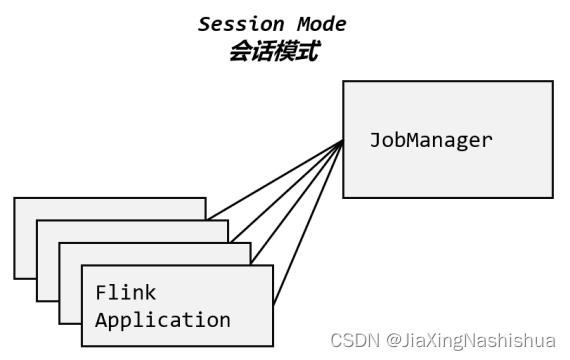
这样的好处很明显,我们只需要一个集群,就像一个大箱子,所有的作业提交之后都塞进 去;集群的生命周期是超越于作业之上的,铁打的营盘流水的兵,作业结束了就释放资源,集 群依然正常运行。当然缺点也是显而易见的:因为资源是共享的,所以资源不够了,提交新的 作业就会失败。另外,同一个 TaskManager 上可能运行了很多作业,如果其中一个发生故障导致 TaskManager 宕机,那么所有作业都会受到影响。
说明:会话模式比较适合于单个规模小、执行时间短的大量作业。
3.2.2 单作业模式( Per-Job Mode)

单作业模式也很好理解,就是严格的一对一,集群只为这个作业而生。同样由客户端运行 应用程序,然后启动集群,作业被提交给 JobManager,进而分发给 TaskManager 执行。作业 作业完成后,集群就会关闭,所有资源也会释放。这样一来,每个作业都有它自己的 JobManager
管理,占用独享的资源,即使发生故障,它的 TaskManager 宕机也不会影响其他作业。
这些特性使得单作业模式在生产环境运行更加稳定,所以是实际应用的首选模式。
需要注意的是, Flink 本身无法直接这样运行,所以单作业模式一般需要借助一些资源管 理框架来启动集群,比如 YARN、 Kubernetes。
3.2.3 应用模式(Application Mode)
前面提到的两种模式(会话模式和单作业模式)下,应用代码都是在客户端上执行,然后由客户端提交给 JobManager的。但是这种方式客户端需要占用大量网络带宽,去下载依赖和把二进制数据发送给JobManager;加上很多情况下我们提交作业用的是同一个客户端,就会加重客户端所在节点的 资源消耗。
所以解决办法就是,我们不要客户端了,直接把应用提交到 JobManger 上运行。而这也就 代表着,我们需要为每一个提交的应用单独启动一个 JobManager,也就是创建一个集群。这 个 JobManager 只为执行这一个应用而存在,执行结束之后 JobManager 也就关闭了,这就是所谓的应用模式

应用模式与单作业模式,都是提交作业之后才创建集群;单作业模式是通过客户端来提交 的,客户端解析出的每一个作业对应一个集群;而应用模式下,是直接由 JobManager 执行应 用程序的,并且即使应用包含了多个作业,也只创建一个集群。
总结一下,在会话模式下,集群的生命周期独立于集群上运行的任何作业的生命周期,并 且提交的所有作业共享资源。而单作业模式为每个提交的作业创建一个集群,带来了更好的资 源隔离,这时集群的生命周期与作业的生命周期绑定。最后,应用模式为每个应用程序创建一 个会话集群,在 JobManager 上直接调用应用程序的 main()方法。
我们所讲到的部署模式,相对是比较抽象的概念。实际应用时,一般需要和资源管理平台 结合起来,选择特定的模式来分配资源、部署应用。接下来,我们就针对不同的资源提供者 (Resource Provider)的场景,具体介绍 Flink 的部署方式。
3.3 独立模式(Standalone)
独立模式( Standalone)是部署 Flink 最基本也是最简单的方式:所需要的所有 Flink 组件, 都只是操作系统上运行的一个 JVM 进程。
独立模式是独立运行的,不依赖任何外部的资源管理平台;当然独立也是有代价的:如果 资源不足,或者出现故障,没有自动扩展或重分配资源的保证,必须手动处理。所以独立模式 一般只用在开发测试或作业非常少的场景下。
另外,我们也可以将独立模式的集群放在容器中运行。 Flink 提供了独立模式的容器化部 署方式,可以在 Docker 或者 Kubernetes 上进行部署。
3.3.1 会话模式部署
可以发现,独立模式的特点是不依赖外部资源管理平台,而会话模式的特点是先启动集群、 后提交作业。所以,我们在第 3.1 节用的就是独立模式(Standalone)的会话模式部署。
3.3.2 单作业模式部署
在 3.2.2 节中我们提到, Flink 本身无法直接以单作业方式启动集群,一般需要借助一些资 源管理平台。所以 Flink 的独立(Standalone)集群并不支持单作业模式部署。
3.3.3 应用模式部署
应用模式下不会提前创建集群,所以不能调用 start-cluster.sh 脚本。我们可以使用同样在
bin 目录下的 standalone-job.sh 来创建一个 JobManager。
$ cp . /FlinkTutorial- 1 . 0 -SNAPSHOT . j ar lib/
(2)执行以下命令,启动 JobManager。
$ . /bin/ standalone-j ob . sh start --j ob-clas sname com . atguigu . wc . StreamWordCount
这里我们直接指定作业入口类,脚本会到 lib 目录扫描所有的 jar 包。
(3)同样是使用 bin 目录下的脚本,启动 TaskManager。
$ . /bin/taskmanager . sh start (4)如果希望停掉集群,同样可以使用脚本,命令如下。
$ . /bin/ standalone-j ob . sh stop
$ . /bin/taskmanager . sh stop
3.4 YARN 模式
独立(Standalone)模式由 Flink 自身提供资源,无需其他框架,这种方式降低了和其他 第三方资源框架的耦合性,独立性非常强。但我们知道, Flink 是大数据计算框架,不是资源 调度框架,这并不是它的强项;所以还是应该让专业的框架做专业的事,和其他资源调度框架 集成更靠谱。而在目前大数据生态中,国内应用最为广泛的资源管理平台就是 YARN 了。所 以接下来我们就将学习,在强大的 YARN 平台上 Flink 是如何集成部署的。
整体来说, YARN 上部署的过程是:客户端把 Flink 应用提交给 Yarn 的 ResourceManager, Yarn 的 ResourceManager 会向 Yarn 的 NodeManager 申请容器。在这些容器上, Flink 会部署
JobManager 和 TaskManager 的实例,从而启动集群。 Flink 会根据运行在 JobManger 上的作业 所需要的 Slot 数量动态分配 TaskManager 资源。
3.4.1 相关准备和配置
在 Flink1.8.0 之前的版本,想要以 YARN 模式部署 Flink 任务时,需要 Flink 是有 Hadoop
支持的。从 Flink 1.8 版本开始,不再提供基于 Hadoop 编译的安装包,若需要 Hadoop 的环境 支持,需要自行在官网下载 Hadoop 相关版本的组件 flink-shaded-hadoop-2-uber-2.7.5-10.0.jar, 并将该组件上传至 Flink 的 lib 目录下。在 Flink 1.11.0 版本之后,增加了很多重要新特性,其 中就包括增加了对Hadoop3.0.0以及更高版本Hadoop的支持,不再提供“flink-shaded-hadoop-*”
jar 包,而是通过配置环境变量完成与 YARN 集群的对接。
在将 Flink 任务部署至 YARN 集群之前,需要确认集群是否安装有 Hadoop,保证 Hadoop
版本至少在 2.2 以上,并且集群中安装有 HDFS 服务。
( 1)下载并解压安装包,并将解压后的安装包重命名为 flink-1.13.0-yarn, 本节的相关操作都将默认在此安装路径下执行。
(2)配置环境变量,增加环境变量配置如下:
$ sudo vim /etc/profile . d/my_env . sh
HADOOP_HOME=/opt/module/hadoop-2 . 7 . 5
export PATH=$PATH : $HADOOP_HOME/bin : $HADOOP_HOME/ sbin
export HADOOP_CONF_DIR=$ { HADOOP_HOME } /etc/hadoop
export HADOOP_CLASSPATH= ` hadoop clas spath `start-dfs . sh
start-yarn . sh
分别在 3 台节点服务器查看进程启动情况。
(4)进入 conf 目录,修改 flink-conf.yaml 文件,修改以下配置,这些配置项的含义在进 行 Standalone 模式配置的时候进行过讲解,若在提交命令中不特定指明,这些配置将作为默认 配置。
3.4.2 会话模式部署
YARN 的会话模式与独立集群略有不同,需要首先申请一个 YARN 会话(YARN session) 来启动 Flink 集群。
1 . 启动集群
( 1)启动 hadoop 集群(HDFS, YARN)。
(2)执行脚本命令向 YARN 集群申请资源,开启一个 YARN 会话,启动 Flink 集群。
$ bin/yarn-ses sion . sh -nm test
可用参数解读:
⚫ -d:分离模式,如果你不想让 Flink YARN 客户端一直前台运行,可以使用这个参数,
44
即使关掉当前对话窗口, YARN session 也可以后台运行。
⚫ -jm(--jobManagerMemory):配置 JobManager 所需内存,默认单位 MB。
⚫ -nm(--name):配置在 YARN UI 界面上显示的任务名。
⚫ -qu(--queue):指定 YARN 队列名。
⚫ -tm(--taskManager):配置每个 TaskManager 所使用内存。注意: Flink1.1 1.0 版本不再使用-n 参数和-s 参数分别指定 TaskManager 数量和 slot 数量,
YARN 会按照需求动态分配 TaskManager 和 slot。所以从这个意义上讲, YARN 的会话模式也 不会把集群资源固定,同样是动态分配的。 YARN Session 启动之后会给出一个 web UI 地址以及一个 YARN application ID,如下所示, 用户可以通过 web UI 或者命令行两种方式提交作业。
2. 提交作业
( 1)通过 Web UI 提交作业
这种方式比较简单,与上文所述 Standalone 部署模式基本相同。
(2)通过命令行提交作业
① 将 Standalone 模式讲解中打包好的任务运行 JAR 包上传至集群
② 执行以下命令将该任务提交到已经开启的 Yarn-Session 中运行。
$ bin/ flink run
-c com . atguigu . wc . StreamWordCount FlinkTutorial- 1 . 0 -SNAPSHOT . j ar
客户端可以自行确定 JobManager 的地址,也可以通过-m 或者-jobmanager 参数指定
JobManager 的地址, JobManager 的地址在 YARN Session 的启动页面中可以找到。
③ 任务提交成功后,可在 YARN 的 Web UI 界面查看运行情况。
3.4.3 单作业模式部署
在 YARN 环境中,由于有了外部平台做资源调度,所以我们也可以直接向 YARN 提交一 个单独的作业,从而启动一个 Flink 集群。
( 1)执行命令提交作业。
$ bin/ flink run -d -t yarn-per-j ob -c com . atguigu . wc . StreamWordCount FlinkTutorial- 1 . 0 -SNAPSHOT . j ar早期版本也有另一种写法:
$ bin/ flink run -m yarn-cluster -c com . atguigu . wc . StreamWordCount FlinkTutorial- 1 . 0 -SNAPSHOT . j ar注意这里是通过参数-m yarn-cluster 指定向 YARN 集群提交任务。
(2)在 YARN 的 ResourceManager 界面查看执行情况
(3)可以使用命令行查看或取消作业
3.4.4 应用模式部署
( 1)执行命令提交作业。
(2)在命令行中查看或取消作业。
(3)也可以通过 yarn.provided.lib.dirs 配置选项指定位置,将 jar 上传到远程。