异步 PHP — 多进程、多线程和协程
让我们看一下这段典型的 PHP 代码:
function names()
{
$data = Http::get('data.location/products')->json();
$names = [];
foreach ($data as $item){
$names[] = $item['name'];
}
return $names;
}
我们发送一个返回项目数组的 HTTP 请求,然后我们将每个项目的名称存储在一个 $names 数组中。
执行此函数所花费的时间等于请求的持续时间加上构建数组所花费的时间。如果我们想为不同的数据源多次运行这个函数怎么办:
$products = names('/products');
$users = names('/users');
运行此代码所花费的时间等于两个函数组合的持续时间:
HTTP request to collect products: 1.5 seconds Building products names array: 0.01 seconds HTTP request to collect users: 3.0 seconds Building users names array: 0.01 seconds Total: 4.52 seconds
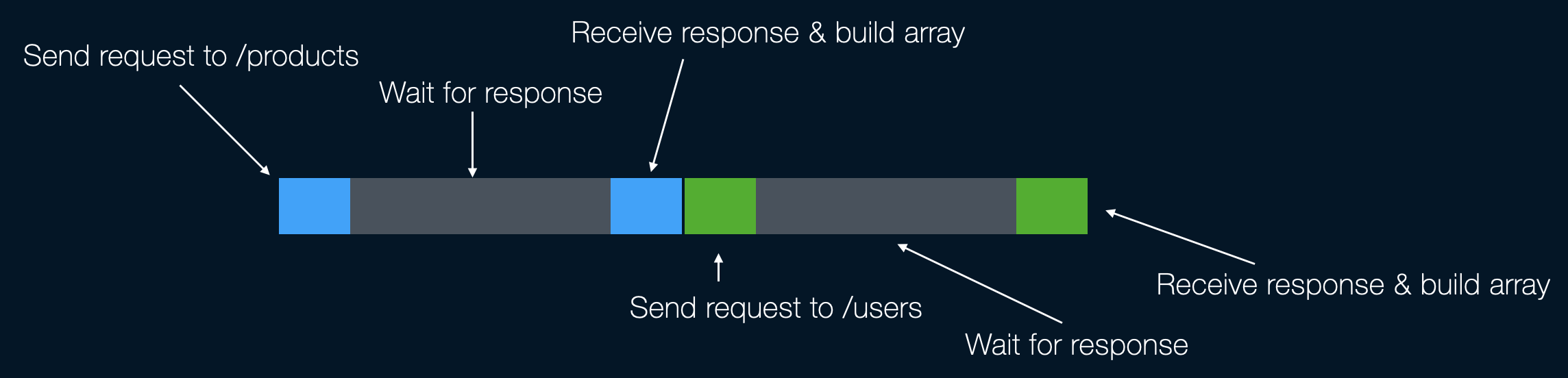
这称为同步代码执行,或一次执行一件事。为了使此代码运行得更快,您可能希望异步执行它。那么,如果我们想实现这一目标,我们有哪些选择呢?
- 在不同的进程中执行。
- 在不同的线程中执行。
- 在协程/纤维/绿色线程中执行。
在不同的进程中执行
在单独的进程中运行这些函数调用中的每一个,都会为操作系统提供并行运行它们的任务。如果您有一个多核处理器,我们现在都有,并且周围有 2 个空闲内核,操作系统将使用两个内核并行(同时)执行进程。但是,在大多数情况下,机器上运行的其他进程需要使用可用的内核。在这种情况下,操作系统将在这些进程之间共享 CPU 时间。换句话说,可用内核将在处理我们的两个进程和其他进程之间切换。在这种情况下,我们的进程将同时执行。
这两个进程的执行时间大约是 3.03 秒(我知道不是 100% 准确)。这个结论是基于这样一个事实:最慢的请求需要 3 秒,2 次网络调用需要 10 毫秒,两个用于收集名称的循环各需要 10 毫秒。
核心内部的执行将如下所示:
Switch to process 1 Start HTTP request to collect products Switch to process 2 Start HTTP request to collect users Switch to process 1 If a response came, then build products names array Switch to process 2 If a response came, then build users names array
因此,当 CPU 等待第一个请求的响应时,它会发送第二个请求。然后等到任何请求返回,然后再继续该过程。
多处理是在 PHP 中实现异步代码执行的一种简单方法。但是,它并不是性能最高的。因为创建进程相对昂贵,并且每个进程都需要在内存中拥有自己的私有空间。进程之间的切换(上下文切换)也有开销。
您可以使用Laravel 队列并启动固定数量的工作人员(进程)并让它们保持活动状态以处理您的任务。这样你就不必每次想要异步运行时都创建新进程。但是,上下文切换和内存分配的开销仍将适用。同样对于工作人员,您需要管理如何从工作人员内部的代码执行中接收结果。
多处理和 Laravel 工作人员已经为数百万个应用程序做得很好。因此,当我说它不是相对于其他选项时性能最好的。不要只是阅读本文并认为多处理和队列不好。好?
在不同的线程中执行
一个进程在内存中有自己的私有空间,一个进程可能有多个线程。所有线程都与进程位于相同的内存空间中。这使得生成线程比生成进程更便宜。
但是,上下文切换仍然会发生。当你有太多线程时,比如有太多进程,你机器上的一切都会变慢。因为 CPU 内核在很多上下文之间切换。
此外,由于多个线程同时访问相同的内存空间,可能会发生争用情况。
除此之外, 不再支持 PHP 中的多线程。
在 coroutines/fibers/green-threads 中执行
这个“东西”有很多名字。但是我们称它为“协程”,因为它是最常用的术语。
协程就像一个线程,它共享它在内部创建的进程的内存,但它不是一个实际的线程,因为操作系统对此一无所知。操作系统级别的协程之间没有上下文切换。运行时控制切换发生的时间,这比 OS 上下文切换成本更低。
让我们将代码转换为使用协程。此代码仅用于演示,如果您运行它将不起作用:
$products = [];
$users = [];
go(fn() => $products = names('/products'));
go(fn() => $users = names('/users'));
协程背后的想法是运行时将安排同时运行这些回调。在每个协程内部,代码可以显式地将控制权交给运行时,以便它可以运行另一个协程。在任何给定时间,只有一个协程正在执行。
所以如果我们分解我们的代码,它会是这样的:
go(function(){
$data = Http::get('data.location/products')->json();
// yields
foreach(...)
});
go(function(){
$data = Http::get('data.location/users')->json();
// yields
foreach(...)
});
运行时将执行第一个协程直到它产生,然后执行第二个协程直到它产生,然后返回到它在第一个协程中停止的位置。直到所有协程都执行完毕。然后,它将以常规同步方式继续执行代码。
现在你可能有两个问题;首先,什么时候应该屈服?第二,我们如何实现它?
在我们的示例中,每个协程内部都有两个操作;一个 I/O 绑定和一个 CPU 绑定。发送 HTTP 请求是一个 I\O 绑定操作,我们发送请求(输入)并等待响应(输出)。另一方面,循环是一个 CPU 密集型操作,我们正在循环一组记录并计算结果。计算是由 CPU 完成的,这就是为什么它被称为 CPU bound。
如果在同一进程中运行,受 CPU 限制的工作将花费相同的时间。使工作花费更少时间的唯一方法是在不同的进程或线程中执行它。另一方面,I\O 绑定的工作可以在同一个进程内并发运行;当一个 I\O 操作正在等待输出时,另一个操作可以开始。
查看我们的示例,运行时内部的执行将如下所示:
Start coroutine 1 Start HTTP request to collect products Coroutine 1 yields Switch to coroutine 2 Start HTTP request to collect users Coroutine 2 yields Switch to coroutine 1 If a response came, then build products names array Switch to coroutine 2 If a response came, then build users names array
使用协程,我们可以将 I\O 操作花费在等待上的时间用于做其他工作。通过这样做,我们同时运行所有协程。
现在让我们转向我们的第二个问题:我们如何使屈服发生?我们没有。
不同的框架和库必须通过在 I\O 操作等待时让出控制来支持异步执行。有一个流行的术语,你应该知道“非阻塞 I\O”。与数据库、缓存、文件系统、网络等通信的库必须适应非阻塞。
如果您在协程中使用阻塞库,它将永远不会产生,因此您的协程将同步执行。主进程将等到 I\O 操作收到输出,然后再继续程序的其余部分。
结论
关于协程和异步执行还有很多话要说。我的计划是探索如何让 Laravel 与协程很好地配合,并在此过程中分享我的发现。
在那之前,拥抱 PHP 的同步代码执行。超过 25 年,它运行良好。将您需要剪切的 I\O 绑定工作发送到队列工作程序并稍后对结果采取行动。这应该涵盖许多用例。