推荐系统中的特征工程
摘要:深度学习时期,与CV、语音、NLP领域不同,搜推广场景下特征工程仍然对业务效果具有很大的影响,并且占据了算法工程师的很多精力。数据决定了效果的上限,算法只能决定逼近上限的程度,而特征工程则是数据与算法之间的桥梁。本文尝试总结一些在推荐场景下做特征工程的常用套路,包括常用的特征变换算子、Bin-Counting技术以及特征查漏补缺的方法。
读者受益
- 深入理解常用的特征变换操作。
- 了解优质特征工程的判断标准。
- 掌握推荐场景下构建高质量特征的一般方法。
一、为什么要精做特征工程
在完整的机器学习流水线中,特征工程通常占据了数据科学家很大一部分的精力,一方面是因为特征工程能够显著提升模型性能,高质量的特征能够大大简化模型复杂度,让模型变得高效且易理解、易维护。在机器学习领域,“Garbage In, Garbage Out”是业界的共识,对于一个机器学习问题,数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。

在一个完整的机器学习流水线中,特征工程处于上游位置,因此特征工程的好坏直接影响后续的模型与算法的表现。另外,特征工程也是编码领域专家经验的重要手段。
关于特征工程的三个误区:
1. 误区一:深度学习时代不需要特征工程
深度学习技术在计算机视觉、语音、NLP领域的成功,使得在这些领域手工做特征工程的重要性大大降低,因此可能会有人觉得深度学习时代不再需要人工做特征工程。然后,在搜索、推荐、广告等领域,特征数据主要以关系型结构组织和存储,在关系型数据上的特征生成和变换操作主要有两大类型,一种是基于行(row-based)的特征变换,也就是同一个样本的不同特征之间的变换操作,比如特征组合;另一种是基于列(column-based)的特征变换,比如类别型特征的分组统计值,如最大值、最小值、平均值、中位数等。
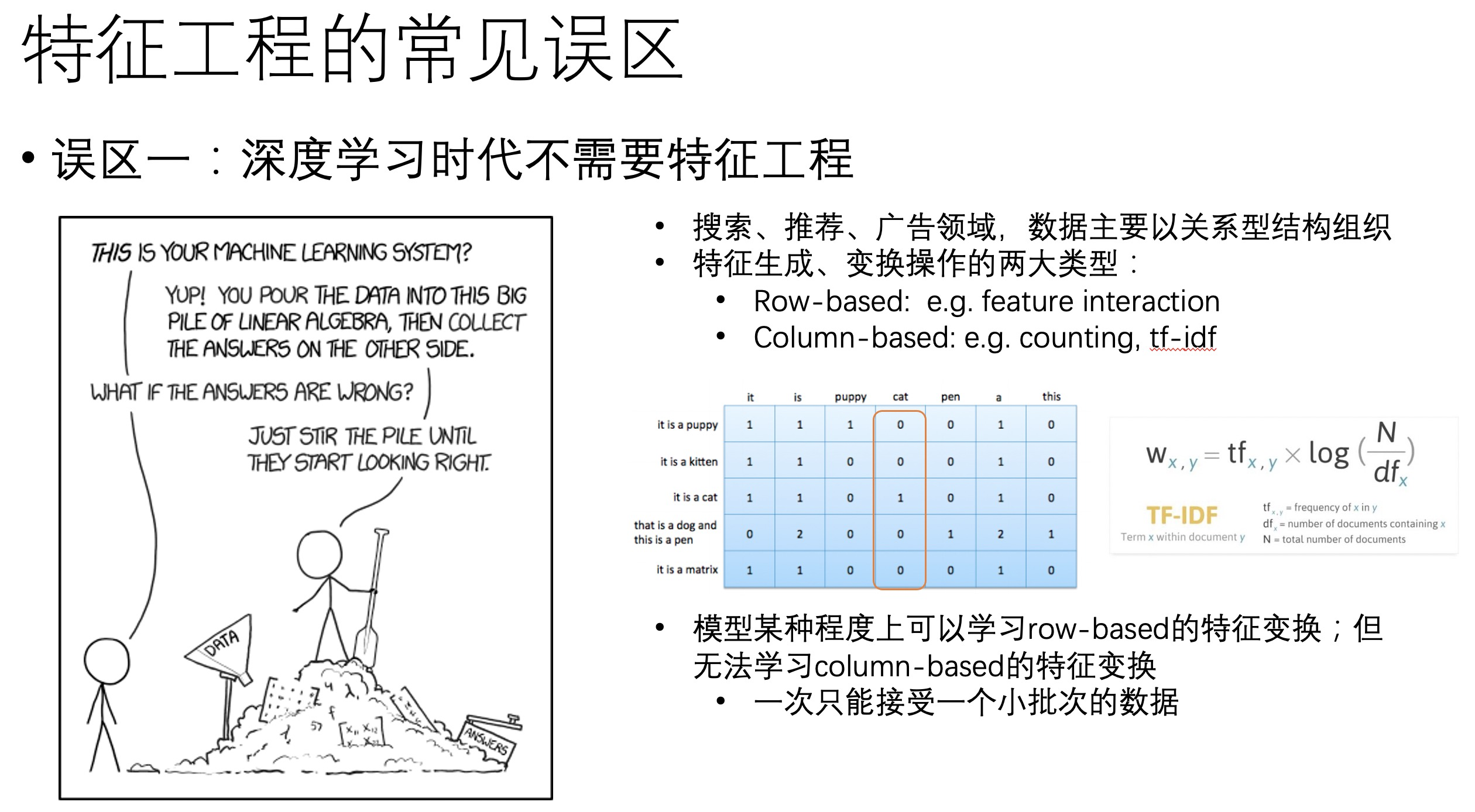
模型可以一定程度上学习到row-based的特征变换,比如PNN、DCN、DeepFM、xDeepFM、AutoInt等模型都可以建模特征的交叉组合操作。尽管如此,模型却很难学习到基于列的特征变换,这是因为深度模型一次只能接受一个小批次的样本,无法建模到全局的统计聚合信息,而这些信息往往是很重要的。综上,即使是深度学习模型也是需要精准特征工程的。
2. 误区二:有了AutoFE工具就不再需要手工做特征工程

3. 误区三:特征工程是没有技术含量的脏活累活
很多学生和刚参加工作不久的同事会有一种偏见,那就是算法模型才是高大上的技术,特征工程是脏活累活,没有技术含量。因此,很多人把大量精力投入到算法模型的学习和积累中,而很少化时间和精力去积累特征工程方面的经验。其实,算法模型的学习过程就好比是西西弗斯推着石头上山,石头最终还会滚落下来,这是因为算法模型的更新迭代速度太快了,总会有效率更高、效果更好的模型被提出,从而让之前的积累变得无用。另一方面,特征工程的经验沉淀就好比是一个滚雪球的过程,雪球会越滚越大,最终我们会成为一个业务的领域专家,对业务贡献无可代替的价值。

机器学习工作流就好比是一个厨师做菜的过程,简单来说,清洗食材对应了清洗数据,食材的去皮、切片和搭配就对于了特征工程的过程,食物的烹饪对应了模型训练的过程。如果你觉得数据清洗和特征工程不重要,莫非是你想吃一份没有经过清洗、去皮、切片、调料,而直接把原始的带着泥沙的蔬菜瓜果放在大锅里乱炖出来的“菜”? 先不说卫生的问题,能不能弄熟了都是个问题。
非常建议大家阅读一下这篇文章《带你轻松看懂机器学习工作流——以“点一份披萨外卖”为例》。
二、什么是好的特征工程
高质量特征需要满足以下标准:
- 有区分性(Informative)
- 特征之间相互独立(Independent)
- 简单易于理解(Simple)
- 伸缩性( Scalable ):支持大数据量、高基数特征
- 高效率( Efficient ):支持高并发预测
- 灵活性( Flexible ):对下游任务有一定的普适性
- 自适应( Adaptive ):对数据分布的变化有一定的鲁棒性
参考:《何谓好的特征》
三、常用的特征变换操作
1. 数值型特征的常用变换
a) 特征缩放
为什么要做特征缩放?
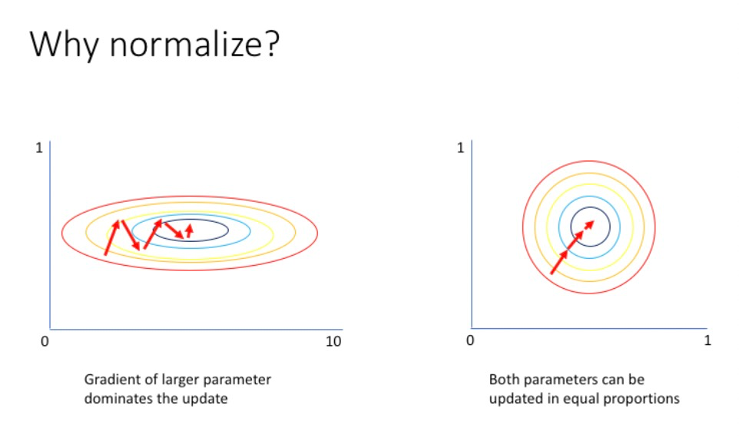
如果不做特征缩放,取值范围较大的特征维度会支配梯度更新的方向,导致梯度更新在误差超平面上不断震荡,模型的学习效率较低。另外,基于距离度量的算法,如KNN,k-means等的效果也会很大程度上受到是否做特征缩放的影响。不做特征缩放,取值范围较大的特征维度会支配距离函数的计算,使得其他特征失去本应有的作用。
常用的特征缩放方法如下:
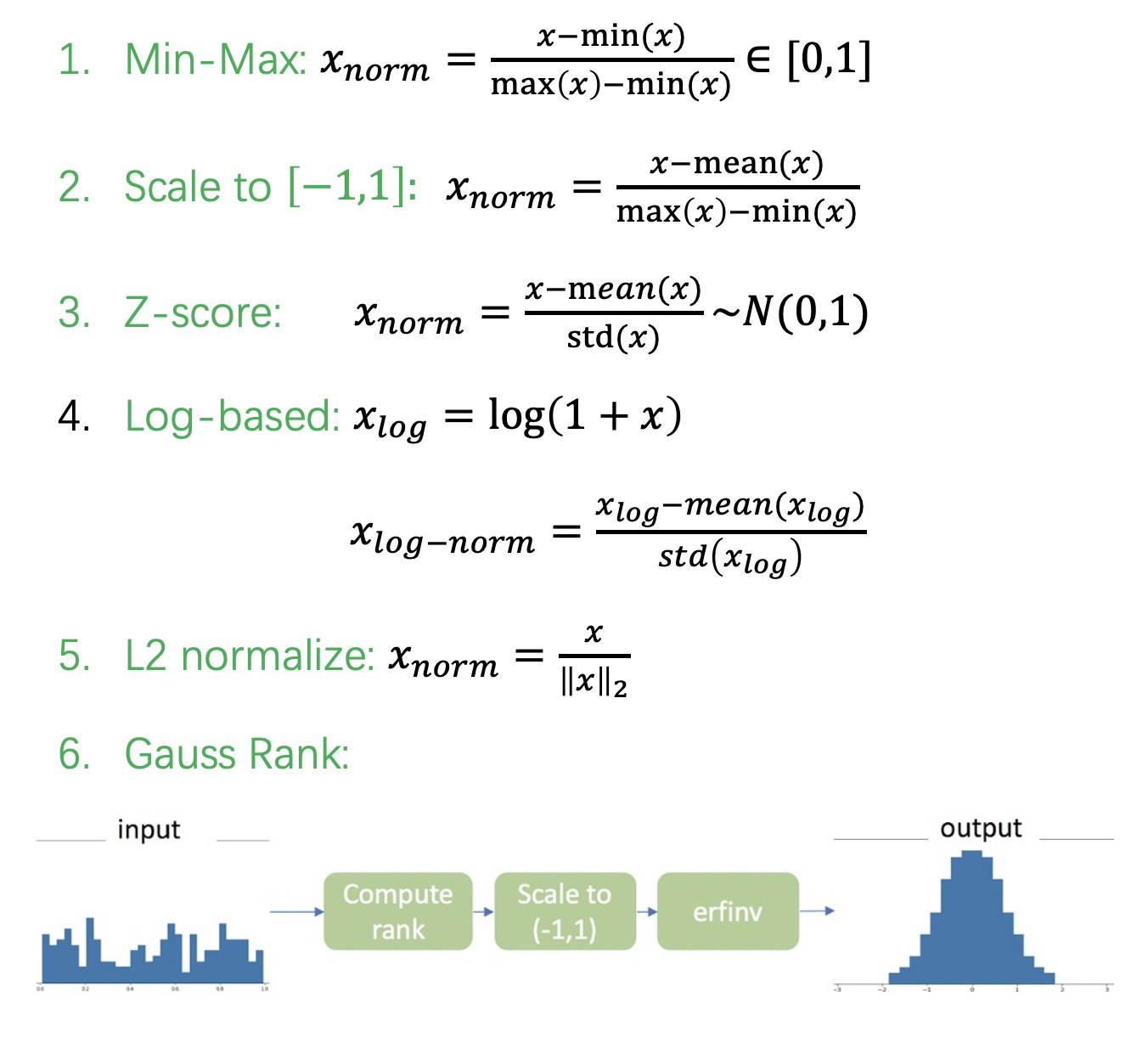
尽管这些特征缩放的方法操作起来都很简单,属于一学就会的内容,但想要达到熟练应用的程度还是比较难的,需要有一定的业务经验的积累,“知行合一”是一种很高的境界。关键在于是否知道在什么场景下该用什么样的特征缩放方法。下面我们通过几个思考题来测试一下自己的掌握程度。
思考题1: 如何量化短视频的流行度(假设就用播放次数来代替)?
参考答案:短视频的播放次数在整个样本空间上遵循幂律分布,少量热门的视频播放次数会很高,大量长尾的视频播放次数都较少。这个时候比较好的做法是先做log based的变换,也就是先对播放次数取log,再对log变换之后的值做z-score标准化变换。如果不先做log变换,就直接做z-score或者min-max变换,会导致特征值被压缩到一个非常狭窄的区域。
思考题2:如何量化商品“贵”或者“便宜”的程度?
参考答案:商品的价格本身无法衡量商品“贵”或“便宜”的程度,因为不同品类的商品价格区间本来就可能差异很大,同样的价格买不同类型的产品给顾客的感受也是不一样的,比如,1000块钱买到一部手机,顾客感觉很便宜;但同样1000块钱买一只鼠标,顾客就会觉得这个商品的定价很贵。因此,量化商品“贵”或者“便宜”的程度时就必须要考虑商品的品类,这里推荐的做法是做z-score标准化变化,但需要注意的是商品价格的均值和标准差的计算都需要限制在同品类的商品集合内。
思考题3:如何量化用户对新闻题材的偏好度?
参考答案:为了简化,假设我们就用用户一段时间内对某类新闻的阅读数量表示用户对该类新闻题材的偏好度。因为不同用户的活跃度是不同的,有些高活跃度用户可能会对多个不同题材的新闻阅读量都很大,而另一些低活跃度的用户可能只对有限的几种类型的新闻有中等的阅读量,我们不能因为高活跃度的用户对某题材的阅读量大于低活跃度用户对相同题材的的阅读量,就得出高活跃度用户对这种类型的偏好度大于低活跃度用户对同类型题材的偏好度,这是因为低活跃度用户的虽然阅读量较少,但却几乎把有限精力全部贡献给了该类型的题材,高活跃度的用户虽然阅读量较大,但却对多种题材“雨露均沾”。建议做min-max归一化,但需要注意的是计算最小值和最大值时都限制在当前用户的数据上,也就是按照用户分组,组内再做min-max归一化。
思考题4:当存在异常值时如何做特征缩放?
当存在异常值时,除了第6种gauss rank特征变换方法外,其他的特征缩放方法都可能把转换后的特征值压缩到一个非常狭窄的区间内,从而使得这些特征失去区分度,如下图。这里介绍一种新的称之为Robust scaling的特征变换方法。
x
s
c
a
l
e
d
=
x
−
m
e
d
i
a
n
(
x
)
I
Q
R
x_{scaled}=\frac{x-median(x)}{IQR}
xscaled=IQRx−median(x)
四分位距(interquartile range, IQR),又称四分差。是描述统计学中的一种方法,以确定第三四分位数和第一四分位数的差值。
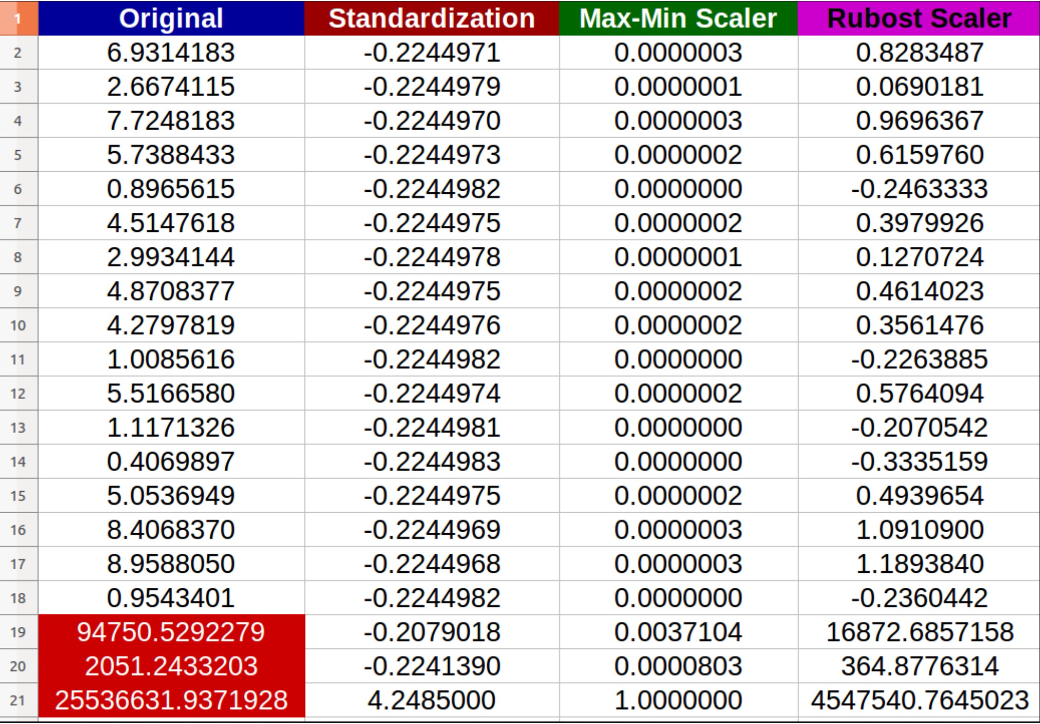
参考答案:存在异常值,使用Robust scaling或者gauss rank的特征缩放方法。
b) 特征分箱(binning)
数值型特征的分箱即特征离散化,按照某种方法把特征值映射到有限的几个“桶(bin)”内。
比如,可以把1天24个小时按照如下规则划分为5个桶,使得每个桶内的不同时间都有类似的目标预测能力,比如有类似的购买概率。
- 0-3 Night: 较低的购买概率
- 4-7 Early morning: 中等的购买概率
- 8-14 Morning/Lunch: 较高的购买概率
- 15-20 Afternoon: 较低的购买概率
- 21-23: Evening: 高购买概率
为什么需要做特征分箱?
- 映入非线性变换,可增强模型的性能
- 增强特征可解释性
- 对异常值不敏感、防止过拟合
- 分箱之后可以对不同的桶做进一步的统计和组合(与其他特征的交叉)
有哪些分箱方法?
- 无监督分箱
- 固定宽度分箱(等宽)
- 分位数分箱(等宽)
- 对数转换并取整(对数)
- 有监督分箱
- 卡方分箱
- 决策树分箱
思考题1:如何度量用户的购买力?如何给用户的购买力划分档位?
背景:用户的购买力衡量的用户的消费倾向,度量用户是愿意花高价买高质量商品还是愿意花低价买便宜商品。购买力属于用户画像的一部分,是比较长期的稳定的,跟近期用户在平台上的消费金额无关。
参考答案:
第一步是给商品划分价格档位。根据商品的类目分组,组类按照商品价格排序,并按照等频或者等宽的分箱方式,得到价格档位。
第二步是聚合用户的购买力档位。根据用户的历史消费行为,把购买商品的价格档位聚合到用户身上。
思考题2:地理位置(经纬度)如何做分箱?
参考答案:一个物理量如何有多个维度才能表示,那么在做分箱时不能拆分成独立的多个变量来单独做分箱,而要这些变量当成一个整体来考虑。经纬度的分箱有一个成熟的算法叫做GeoHash,这里就不展开了。

在推荐系统中,用户的统计特征需要按照用户分组后再做分箱,不建议全局做分箱。在上面的例子中,Bob对不同Category的行为次数都比较高,但却“雨露均沾”,不如Alice对Beauty类目那么专注。如果全局分箱,<Alice, Beauty>、<Bob, Sport>的桶号是不同的,然而Alice对Beauty类目的偏好程度与Bob对Sport类目的偏好程度是差不多的,这两个类目都是彼此的首选。全局分箱会让模型学习时比较困惑。
2. 类别型特征的常用变换
a) 交叉组合
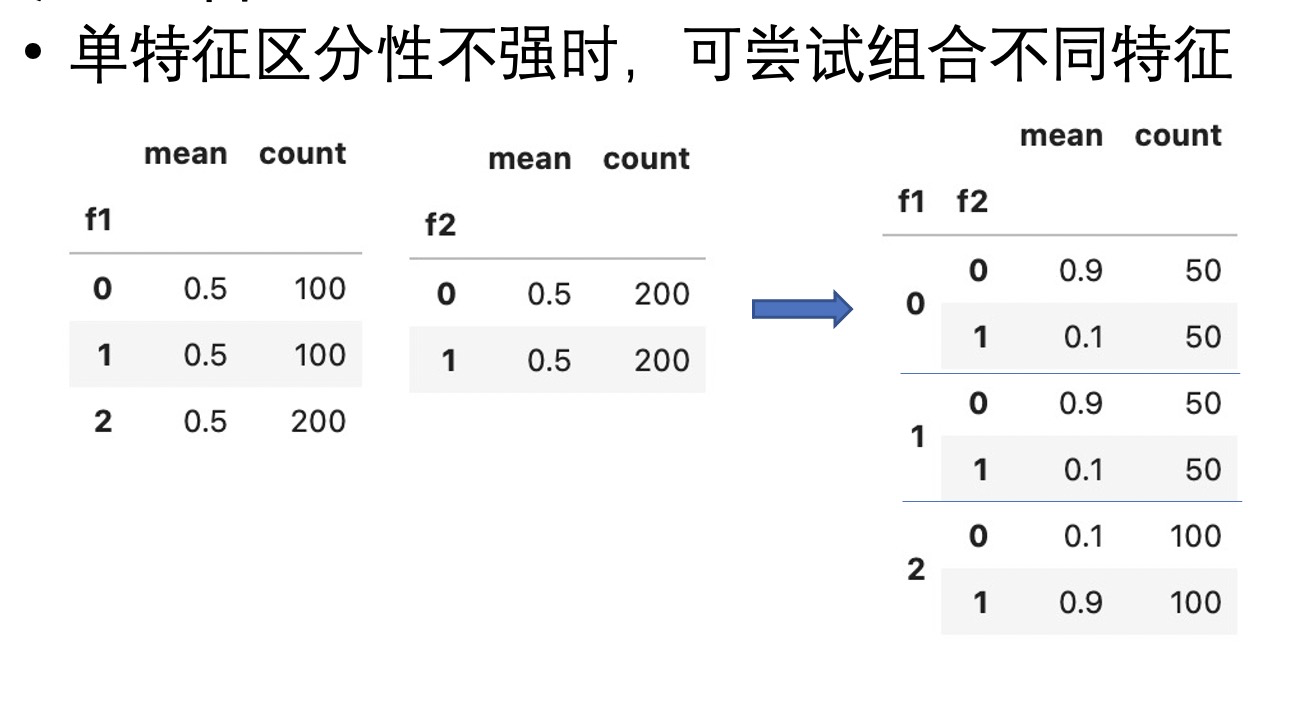
如上图,mean表示预测目标target(二分类)的均值,特征f1和f2单独存在时都不具备很好的区分性,但两种组合起来作为一个整体时却能够对target有很好的预测性。
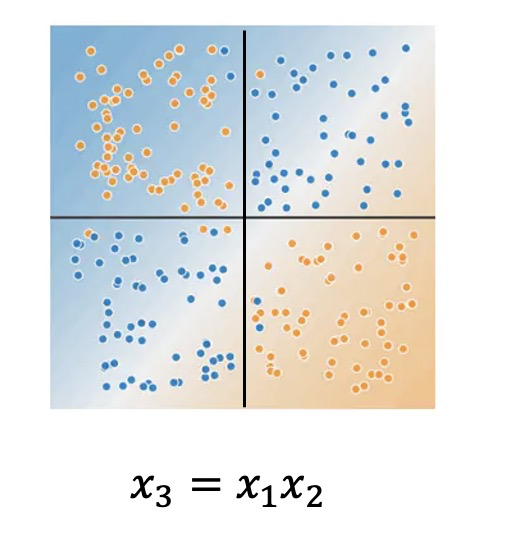
如上图,当只有 x 1 x_1 x1和 x 2 x_2 x2时,目标(用蓝色和黄色分别表示正样本和负样本)不是线性可分的,当引入一个组合特征 x 3 = x 1 x 2 x_3=x_1x_2 x3=x1x2时就可以用 s i g n ( x 3 ) sign(x_3) sign(x3)来预测目标了。
b) 分箱(binning)
高基数(high-cardinality)类别型特征也有必要做特征分箱。这是因为高基数特征相对于低基数特征处于支配地位(尤其在tree based模型中),并且容易引入噪音,导致模型过拟合。甚至一些值可能只会出现在训练集中,另一些可能只会出现在测试集中。
类别型特征的分箱方法通常有如下三种:
- 基于业务理解自定义分箱规则,比如可以把城市划分为华南区、华北区、华东区等。
- 基于特征的频次合并低频长尾部分(back-off)。
- 基于决策树模型。
c) 统计编码
- Count Encoding
统计该类别型特征不同行为类型、不同时间周期内的发生的频次。
- Target Encoding
统计该类别型特征不同行为类型、不同时间周期内的目标转化率(如目标是点击则为点击率,如目标是成交则为购买率)。
目标转化率需要考虑置信度的问题,当置信度不够的时候,需要做平滑,拿全局或者分组的平均转化率当当前特征的转化率做一个平滑,公式如下。

- Odds Ratio
优势比是当前特征取值的优势(odds)与其他特征取值的优势(odds)的比值,公式为: θ = p 1 / ( 1 − p 1 ) p 2 / ( 1 − p 2 ) \theta=\frac{p_1/(1-p_1)}{p_2/(1-p_2)} θ=p2/(1−p2)p1/(1−p1)
假设用户对类目的行为统计数组如下:
| User,Category | Number of clicks | Number of non-clicks |
|---|---|---|
| Alice,1001 | 7 | 134 |
| Bob,1002 | 17 | 235 |
| … | … | … |
| Joe,1101 | 2 | 274 |
那么优势比的计算方法如下:
(
5
/
125
)
/
(
120
/
125
)
(
995
/
19875
)
/
(
18880
/
19875
)
=
0.7906
\frac{(5/125)/(120/125)}{(995/19875)/(18880/19875)}=0.7906
(995/19875)/(18880/19875)(5/125)/(120/125)=0.7906
- WOE(weight of evidence)
WOE度量不同特征取值与目标的相关程度,越正表示越正相关,越负表示越负相关。
W O E = l n ( E v e n t % N o n E v e n t % ) WOE=ln\left( \frac{Event\%}{NonEvent\%} \right) WOE=ln(NonEvent%Event%)

3. 时序特征
- 历史事件分时段统计
- 统计过去1天、3天、7天、30天的总(平均)行为数
- 统计过去1天、3天、7天、30天的行为转化率
- 差异
- 环比、同比
- 行为序列
- 需要模型配合
四、搜推广场景下的特征工程

在搜索、推荐、广告场景下高基数(high-cardinality)属性表示为特征时的挑战
- Scalable: to billions of attribute values
- Efficient: ~10^(5+) predictions/sec/node
- Flexible: for a variety of downstream learners
- Adaptive: to distribution change
为了克服这些挑战,业界最常用的做法是大量使用统计特征,如下:

对各种类别型特征或离散化之后的数值型特征,以及这些特征之间的二阶或高阶交叉组合,按照不同行为类型、不同时间区间、不同目标(针对多目标任务)分别统计正样本和负样本的数量。这些统计量经过特征缩放/分箱和目标编码后可以作为最终特征向量的一部分。推荐的特征缩放方法为gauss rank,或者使用分箱操作。推荐的目标编码方法包括Target Encoding、优势比、WOE等。
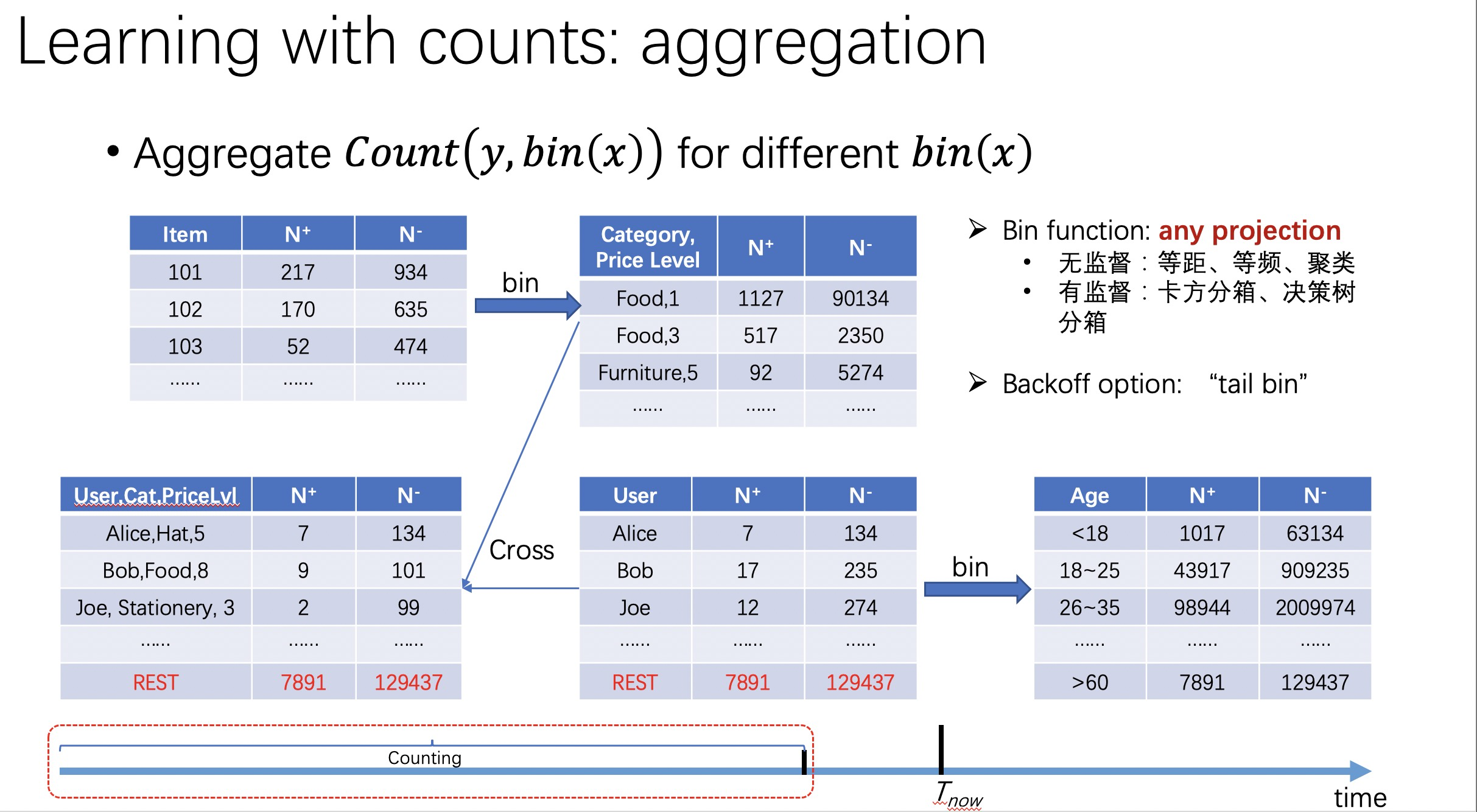
在统计正负样本数量之前,需要对任务涉及的不同实体(如,用户、物品、上下文等)进行分箱,再统计分箱变量的正负样本数量。该操作方法叫做bin counting。这里的binning操作可以是任意的映射函数,最常用的按照实体的自然属性来分箱,比如商品可以按照类目、品牌、店铺、价格、好评率等属性分箱,用户可以按照年龄、性别、职业、爱好、购买力等分箱。
另外,为了防止label leakage,各种统计量的统计时间段都需要放在在样本事件的业务时间之前(注意图片下方的时间轴)。最后把各种粒度的统计量处理(缩放、分箱、编码等)后的值拼接起来作为特征向量的一部分。
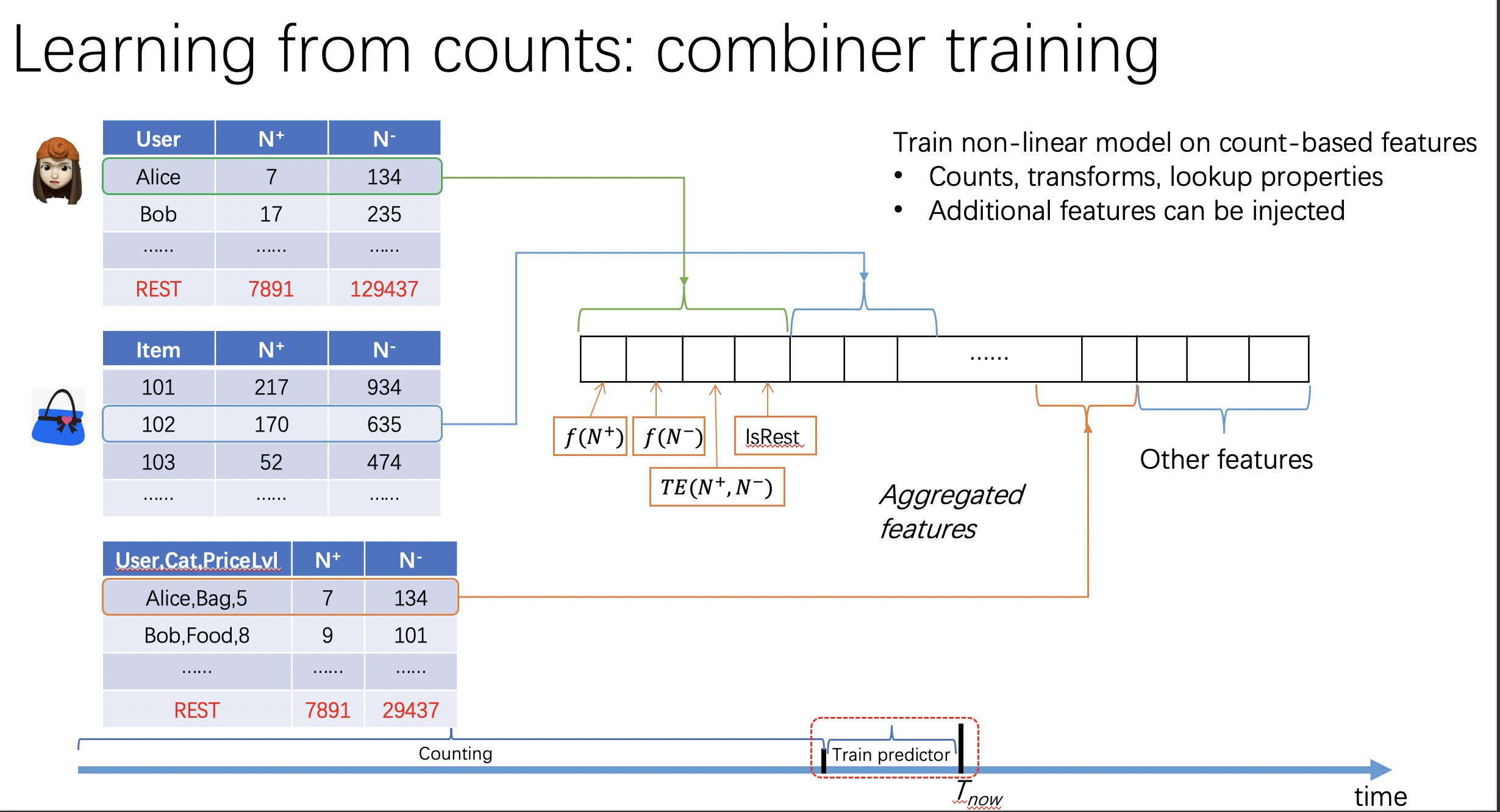
那么,怎么样才能把所有可能的特征都想全了,做到不重不漏呢?可以按照如下描述的结构化方法来枚举特征。
- 列存实体(entity);如果广告业务场景的用户、广告、搜索词、广告平台。
- 实体分箱 & 单维度统计/编码
- 特征交叉 & 多维度统计/编码
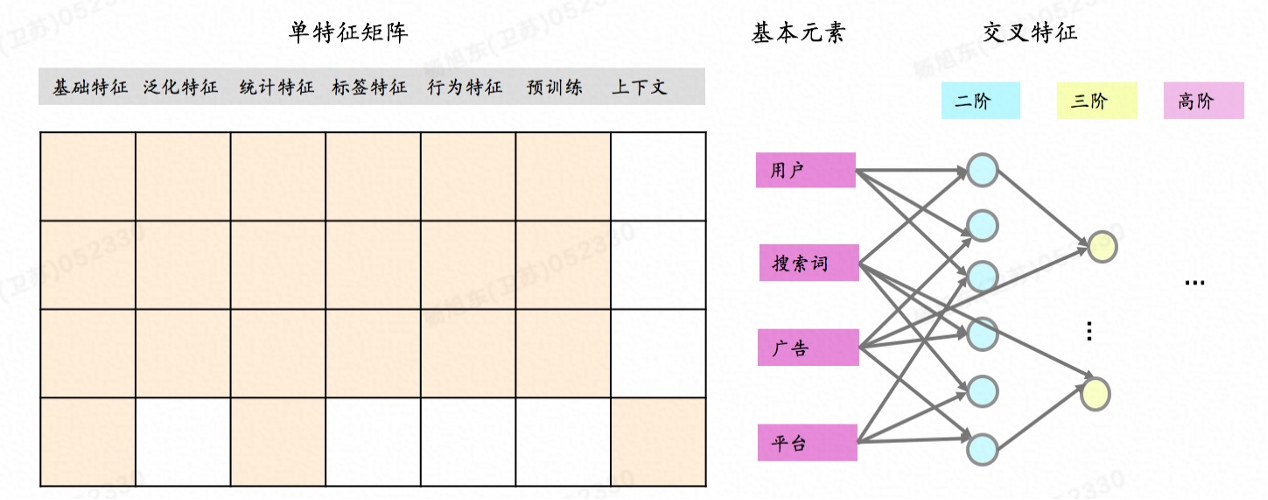
对实体分箱可以玩出很多花样,比如可以从文本描述信息中抽取关键词作为分箱结果;或者可以基于embedding向量聚类,聚类的结果簇作为分箱结果。然后需要对这些分箱结果进行多轮两两交叉得到二阶、三阶或更高阶的组合特征。最后,对这些单维度(一阶)特征和各种高阶组合特征分别统计不同行为类型(点击、收藏、分享、购买等)、不同时间周期(最近1天、3天、7天、30天等)、不同学习目标(点击、转化等)下的正、负样本数量,对这些统计量进行特征缩放、分箱、编码后作为最终的特征。
五、总结
搜推广场景下的常用特征工程套路可以总结为一个词“bin-counting”,也就是先做binning,再做counting,当然别忘了做cross counting。
