《C++程序设计原理与实践》笔记 第5章 错误
本章将讨论程序的正确性、错误和错误处理。
5.1 引言
在编写程序时,错误是不可避免的。而最后的程序必须是没有错误的,至少不存在不可接受的错误。
错误的分类有很多种,例如:
- 编译时错误(compile-time errors):由编译器发现的错误,例如语法错误、类型错误
- 链接时错误(link-time errors):链接器将对象文件链接为可执行程序时发现的错误
- 运行时错误(run-time errors):程序运行中发现的错误,可进一步分为
- 由计算机(硬件或操作系统)检测出的错误
- 由库(例如标准库)检测出的错误
- 由用户代码检测出的错误
- 逻辑错误(logic errors):程序员在寻找错误结果的原因时发现的错误
除非特别说明,我们会假定你的程序:
- 对于所有合法输入应输入正确结果
- 对于所有非法输入应输出错误信息
- 不需要关心硬件故障
- 不需要关心系统软件故障
- 发现错误后允许程序终止
有以下三种方法来编写可接受的软件:
- 精心组织软件结构以减少错误
- 通过调试和测试消除大部分错误
- 确定剩下的错误是不重要的
上述任何一种方法都不能保证完全消除错误,我们必须同时使用上述三种方法。
5.2 错误的来源
- 不够明确(poor specification):如果不具体明确程序应该做什么,就不可能充分检查所有“死角”,并确认所有可能的情况都被正确处理(即对于任意输入都能给出正确结果或者充分的错误信息)。
- 不完备的程序(incomplete programs):在开发过程中,显然会有一些没有考虑到的情况,这是不可避免的。我们必须要达到的目标是知道何时能够处理所有情况。
- 意外的参数(unexpected arguments):如果给函数传递了一个不能处理的参数,就会遇到问题,例如
sqrt(-1.2)。5.5.3节将讨论这类问题。 - 意外的输入(unexpected input):程序通常都会读取数据(来自键盘、文件、GUI、网络连接等)。程序会对输入做很多假设,例如用户会输入一个数字,如果用户输入的不是数字会怎样呢?5.6.3和10.6节将讨论这类问题。
- 意外的状态(unexpected state):大部分程序都会保留很多数据(“状态”)以供系统的不同部分使用,例如4.6.3节读取温度程序中的
vector。如果这些数据是不完整的或者错误的,程序的各个部分仍然应该正常运转。26.3.5节将讨论这类问题。 - 逻辑错误(logical errors):即程序没有按照期望的方式运行,我们必须查找并修正这些问题。6.6和6.9节将给出这类问题的例子。
5.3 编译时错误
在编写程序时,编译器是检查错误的第一道防线。编译器发现的大部分错误都是低级错误。例如,考虑下面这个简单函数的一些调用:
int area(int length, int width); // calculate area of a rectangle
5.3.1 语法错误
如果按照以下方式调用area():
int s1 = area(7, 4; // error: ) missing
int s2 = area(7, 4) // error: ; missing
Int s3 = area(7, 4); // error: Int is not a type
int s4 = area('7, 4); // error: non-terminated character (' missing)
上面每一行都有一个语法错误。即使是一个小错误,编译器也会报告很多繁杂信息,甚至会指向程序中的其他行。因此,如果你在编译器所指向的行中没有发现错误的话,还应该检查一下前几行是否有错误。
对于同样的代码,不同编译器可能会给出不同的错误信息。例如对于s3的声明,Visual Studio使用的MSVC编译器报错如下(与书中给出的错误信息比较接近,也比较难以理解):
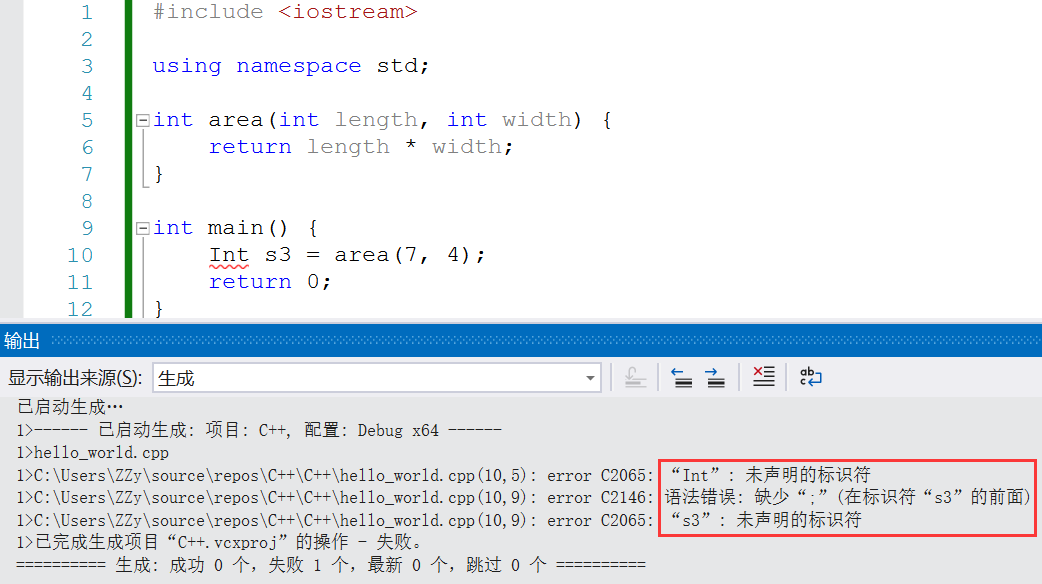
g++编译器报错如下(相比MSVC的错误信息更加“智能”,编译器甚至猜到是将int错误拼写为Int):
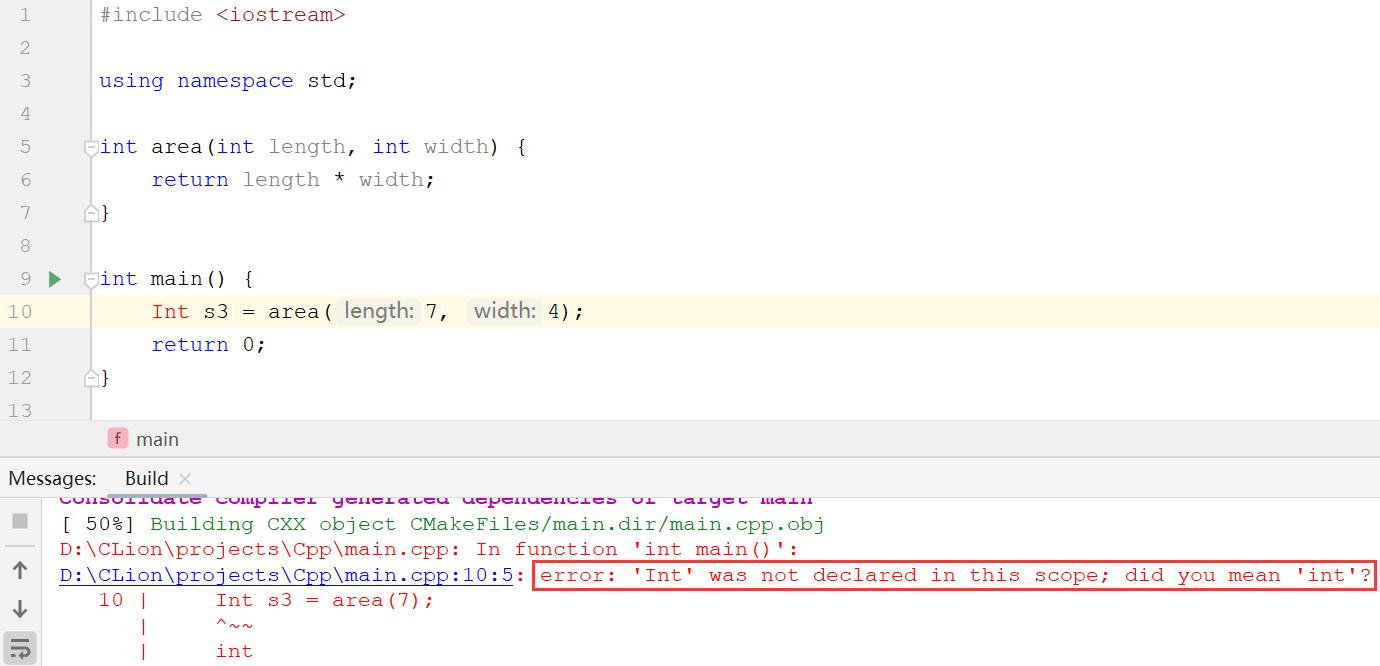
实际上,(MSVC编译器给出的)这些令人费解的信息可以解释为“在s3前有一个语法错误,需要检查一下Int或s3的类型”,这样理解就不难发现问题了。
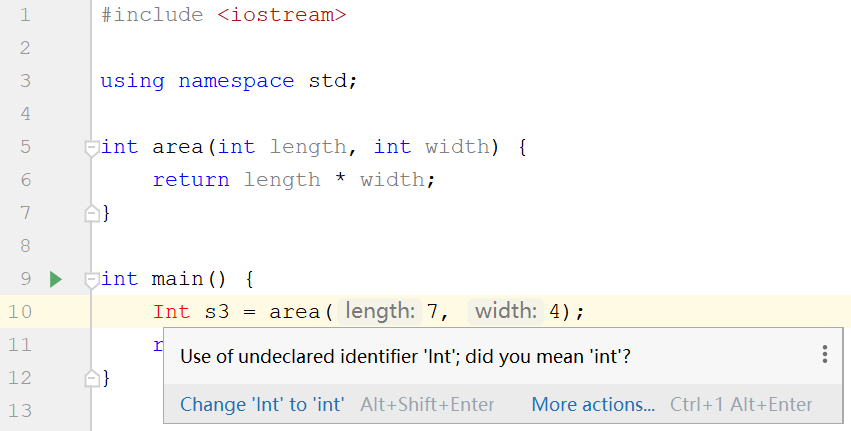
注:如果使用IDE写代码,在编译之前IDE就能发现一些错误。例如Visual Studio的提示为

CLion的提示为
5.3.2 类型错误
一旦排除了语法错误,编译器就会开始检查类型错误:即声明的变量、函数等的类型,以及赋值给变量、传递给函数参数的值或表达式的类型之间不匹配。例如:
int x0 = arena(7); // error: undeclared function
int x1 = area(7); // error: wrong number of arguments
int x2 = area("seven",2); // error: 1st argument has a wrong type
- 对于
arena(7),我们将area错写为arena,因此编译器会认为是调用函数arena。如果没有名为arena的函数,将会得到未定义函数的错误信息;如果确实有叫做arena的函数,并且该函数接受7作为参数,这将是一个更坏的情况:程序将会正确编译,但不会按照预期的方式运行(这是一个逻辑错误)。 - 对于
area(7),编译器将检测到参数个数错误。在C++中,函数调用必须提供正确的参数个数、类型和顺序。 - 对于
area("seven",2),第一个参数声明为int类型,但提供了string,编译器不会识别出"seven"表示的是数字7。
5.3.3 警告
你可能会希望编译器报告的一些错误并不是真正的错误,但是当你有了一定的编程经验后,你会希望编译器能够拒绝更多代码,而不是更少。考虑下面的例子:
int x4 = area(10,–7); // OK: but what is a rectangle with a width of minus 7?
int x5 = area(10.7,9.3); // OK: but calls area(10,9)
char x6 = area(100,9999); // OK: but truncates the result
- 对于
x4,我们没有从编译器得到错误信息。对于编译器来说,area(10,–7)是正确的:area()需要两个整数,也提供了两个整数。没有人规定这些参数必须是正数。 - 对于
x5,好的编译器应该给出警告信息:double型参数10.7和9.3将被截断为int型参数10和9。C++允许从double到int的隐式转换,因此编译器不会拒绝该函数调用。 - 对于
x6,int类型的返回值999900被赋给一个char变量,x6最有可能的结果是截断后的值-36。同样,好的编译器应该给出警告信息。
5.4 链接时错误
一个程序一般由几个独立编译的部分组成(例如一个.cpp源文件或.h头文件),称为翻译单元(translation unit)。程序中的每个函数在所有被使用的翻译单元中的声明类型必须严格一致,我们使用头文件来保证这一点,详见8.3节。并且,每个函数只能定义一次。如果违反任意一条规则,链接器将报错。例如:
// main.cpp
int area(int length, int width);
int main() {
int x = area(2, 3);
}
如果直接将该源文件编译并链接为可执行文件,链接器将报错找不到area()的定义(编译器不会报错,因为编译器只关心函数调用与声明是否一致,不需要函数定义)。
参考:GCC编译器的使用方法
area()的定义与调用必须具有严格相同的类型(包括返回值类型和参数类型):
int area(int x, int y) { /* ... */ } // “our” area()
double area(double x, double y) { /* ... */ } // not “our” area()
int area(int x, int y, char unit) { /* ... */ } // not “our” area()
函数的链接规则同样适用于程序的其他实体,例如变量和类型:同一名字的实体只能有一个定义,但可以有多个声明,并且所有声明的类型必须相同。