CLIP扩展
Audio CLIP:Extend CLIP to Image,Text and Audio(语音)
在已有的image、text 的基础上又加上了audio语音模态。
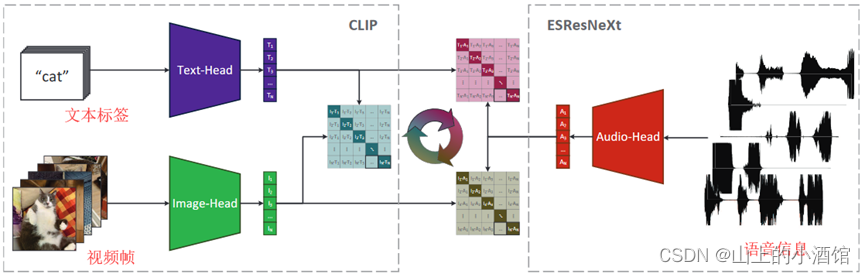
找了一些视频,有视频帧(图像)、文本、语音三种模态的信息,仿照CLIP的模型结构。三种模态两两配对(对角线为正样本对)。最后将三个损失函数相加来更新模型参数。最后可以zero-shot 的做语音分类任务。
point CLIP:Point Cloud Understanding by CLIP(3D)CVPR2021
3D的数据集较小,难以学到很好的表征。如何把CLIP学到的非常好的2D的表征迁移到3D领域?关键就在于找一个2D和3D的“桥梁”。
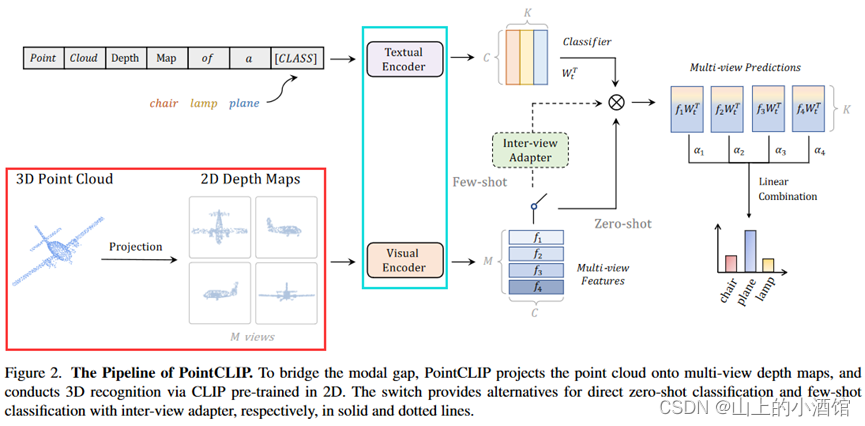
作者将3D点图以不同角度投影到2D深度图上,前边CLIPpasso讲过,由于CLIP模型在特别大的数据集上预训练,因此对各种风格的RGB图像都能提取很好的特征,这里的2D深度图也不例外。
Depth CLIP:Can Language Understand Depth ?(深度信息)CVPR2022
CLIP对物体非常敏感,例如篮球、足球、飞机,CLIP模型是一定可以提取很好的特征,不论是分割还是检测任务都能做的很好。但是对于一些抽象的概念,CLIP模型的表现可能就差强人意。因为对比学习的方式可能确实不适合学一个概念。
与其把深度估计看成一个回归问题,不如将其看成一个分类问题。强制性的把深度距离(抽象概念)分成几个大类(giant 、close、…、 far、unseen七个类)。
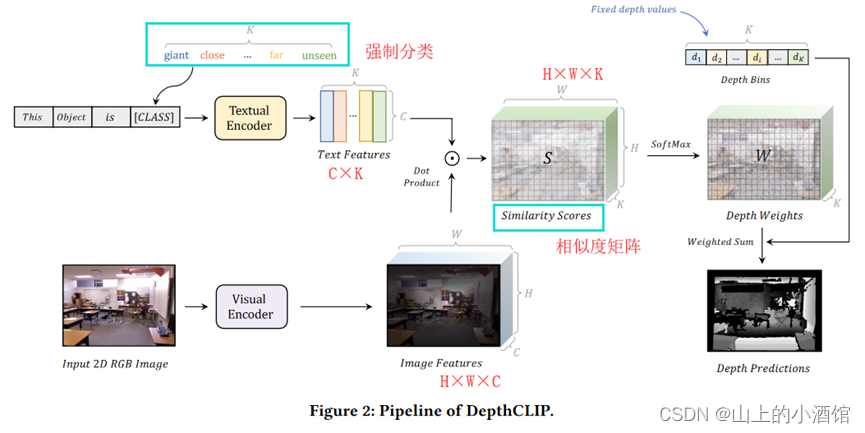
CLIP模型改动的三点
1.改动最小,目前的图像和文本经过CLIP的预训练模型(CLIP预训练数据集比较大,直接使用预训练的参数非常好),得到一个特别好的特征。然后用这个特征做一下点乘或拼接(融合),之前的模型不动,用一个更好的特征加强之前模型的训练。
2.知识蒸馏,将CLIP模型作为teacher网络,生成伪标签。帮助现有的模型收敛更快。
3.不借鉴CLIP的预训练参数,而是借用CLIP这种多模态的对比学习思想(图像文本对,对角线GT)。然后用在自己的任务中,定义自己的正负样本对,然后去算多模态对比学习loss。
参考:CLIP 改进工作串讲(下)【论文精读】_哔哩哔哩_bilibili
论文下载:http://arxiv.org/abs/2107.06383
http://arxiv.org/abs/2106.13043
http://arxiv.org/abs/2112.02413
http://arxiv.org/abs/2207.01077