【图灵MySQL】深入理解Mysql索引底层数据结构与算法
【图灵MySQL】深入理解Mysql索引底层数据结构与算法
索引数据结构二叉树、红黑树、Hash、B+树详解
1. 什么是索引?
2. 二叉树
3. 红黑树
4. Hash、B+树
B树
B+树
B+树在MySQL中默认页节点的大小是多少?千万级别的数据最多需要几次IO?
Hash
MyISAM与Innodb存储引擎底层索引实现区别
MyISAM 与 InnoDB 区别(重点)
MyISAM
InnoDB
MySQL的索引分类
1. 按照功能划分
(1)普通索引
(2)唯一性索引
(3)主键索引
(4)全文索引
2. 按照物理实现划分
(1)聚集索引(聚簇索引)
(2)非聚集索引(非聚簇索引)
为什么建议InnoDB表必须建主键?
为什么推荐使用整型的自增主键?为什么不用UUID?
整型的原因
自增的原因
为什么非主键索引结构叶子节点存储的是主键值?
联合索引的底层存储结构长什么样?
索引数据结构二叉树、红黑树、Hash、B+树详解
1. 什么是索引?
索引是帮助MySQL高效获取数据的排好序的数据结构。
“排好序” 这三个字其实就是对索引最好的形容和体现。
我们可以简单把索引比喻成为书本的目录页,当然这么说太过于抽象,并没有把索引的底层特性说明白,下面我们将依次分析 二叉树、红黑树、Hash、B树、B+树 这些数据结构,来说明索引究竟是什么?!
2. 二叉树
本身是有序树,树中包含的各个节点的度不能超过 2,即只能是 0、1 或者 2。
如果说我们用二叉树作为索引,它的储存结构如下所示:
由于MySQL是放在磁盘里面的,每次查找下一个节点都要经过一次IO操作!假设我们要查找值为5索引,自然是要经过3次的IO。
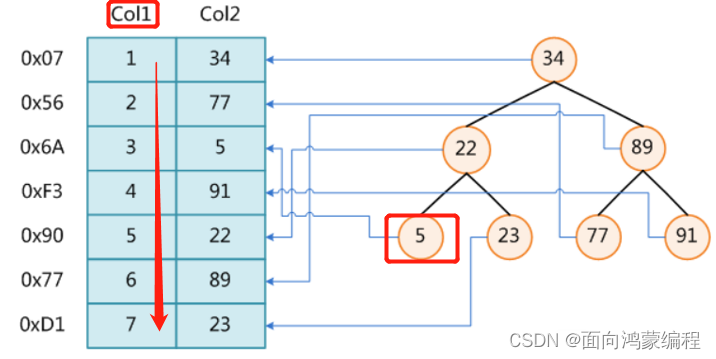
上述案例这样子看起来很合理,查找效率似乎可以控制在logn,但是真的是这样吗?
假设我插入的索引数据是有序的呢?
Binary Search Tree Visualization (usfca.edu)
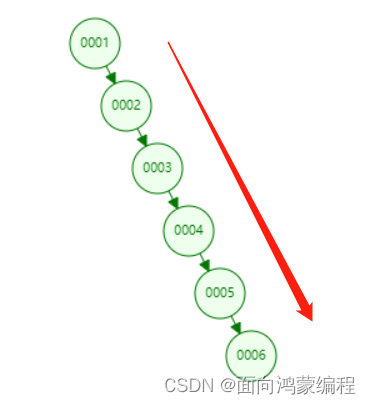
显然,如果是有序的数据,那么二叉树将会退化成链表!
查询5这个节点从原来的3次IO,变成了5次IO!所以这就是使用该数据结构的最大的弊端!!!对于提升查找效率来说并没有太大的帮助。
这时候我们就会想 “如果对二叉树做一下限制,让它成为一颗平衡的二叉树不就好了?”
3. 红黑树
我们自然而然的会想到平衡二叉树(AVL),但是我们这边要说的是红黑树。
红黑树是一种特殊的AVL,它不会遵循AVL过于苛刻的“平衡规则”,而是用自己的一套红黑规则来实现平衡!而且在实现的效率上来看,是要优于AVL的!
但是同样它也不是最优的解决方案!!!
在数据库中,如果数据量比较大的情况下,假设有2000万条记录,那么该树将会达到24层!

看起来好像没有什么的,也就只有24层而已。
但是不要忘了,MySQL数据&索引是存放在磁盘上的,不是Java代码可以放在内存中处理,每多一层就会多做一次IO!
显然红黑树也不是最佳的选择,分析完红黑树的情况,我们也发觉了,要想真正提升查找效率,既要保持平衡,又要减少IO次数(根本)。
4. Hash、B+树
我们使用Navicat工具创建表的时候,为某一个或者某一些字段创建索引,可以选择的索引方法有且仅有两种——B+树 和 Hash
显然这两种数据结构都是MySQL所“认可”的!

B树
基于上面提到的红黑树,解决了“斜树”的问题,但是当数据量达到千万级别的时候,需要的IO次数太多,会导致性能骤降!
所以我们期望中的数据结构,既要满足平衡,又要尽可能减少IO次数。
B树正好符合这一点!
我们来看看B树的数据结构

- 叶节点具有相同的深度,叶节点的指针为空
- 所有索引元素不重复
- 节点中的数据索引从左到右递增排列
B+树
但是B树依然不是最佳的选择,我们先来看看B+树,再分析原因
B+树就是的B树的变种
非叶子节点不存储data,只存储索引(冗余),可以放更多的索引(最大的区别)
叶子节点包含所有索引字段
叶子节点用指针连接,提高区间访问的性能
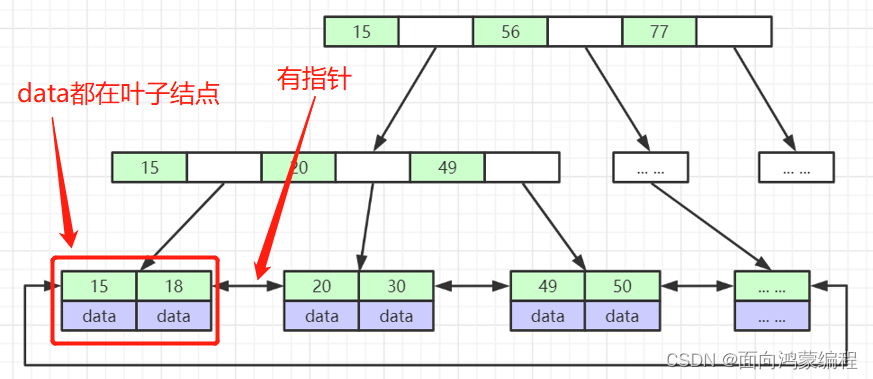
综上所述,B+树这种数据结构确实是比较适合MySQL
B+树在MySQL中默认页节点的大小是多少?千万级别的数据最多需要几次IO?
show global status like 'Innodb_page_size'
-- Innodb_page_size 16384通过这一条语句可以查看到,默认的页节点大小为 16KB

如果我们一个 bigint类型的主键作为索引,它大概是8个字节;白色框框指向下一个节点,存放的是下一个节点的地址,它大概是6个字节。
16KB / ( 8B + 6B ) = 1170个
叶子节点会比较大,含有data,所以我们不妨假设一个(索引+data)有1KB,那么整个叶子节点可以存16个索引。
当B+树为三层的情况下,最多可以存放 1170 * 1170 * 16 = 21,902,400 个
也就是说千万级别的表,我们只要经过3次磁盘IO就可以拿到想要的数据了!
提问:有人又会问了,那数据量更大的情况下呢???
那就再加一层呗~~~当B+树为4层的时候,可以装得下巨量的数据。
但是一般不这么干,当数据量达到千万级别了,我们基本上都是要分库分表的!至于怎么分?如何分?再在下一节中讲到。
Hash
这种索引也是MySQL支持的,但是很少用!而且是99%的情况下是不使用它的!!!
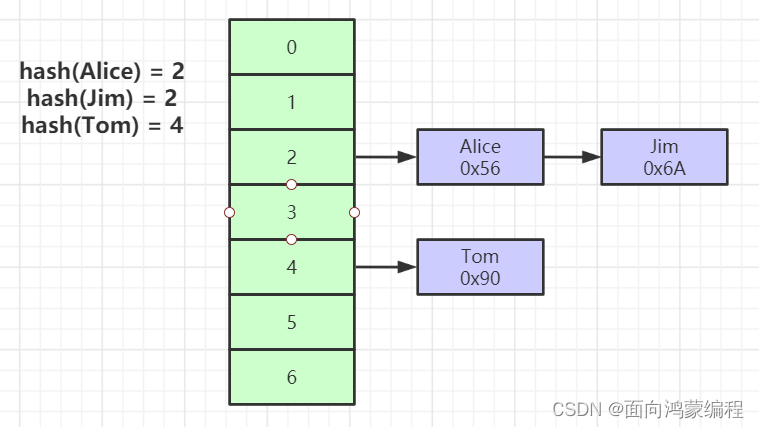
对索引的key进行一次hash计算就可以定位出数据存储的位置,换句话说就是一次IO就可以拿到数据。很多时候Hash索引要比B+ 树索引更高效
很少被使用的原因
- 仅能满足 “=”,“IN”,不支持范围查询(硬伤!!!)
- hash冲突问题
但是B+树可以,看下图,假如要找20~50之间的data,首先B+树是有序的,我们只要找到 20 和 50所在的页结点,它们之间的data就是我们需要的。
页节点之间是有指针的,我们可以“横向”访问。

MyISAM与Innodb存储引擎底层索引实现区别
首先,注意一个常识性的问题!存储引擎是形容数据表的!
虽然在“库”的层面上,也可以设计一个存储引擎,但是真正生效的还是表级别的引擎!!!
CREATE TABLE test_innodb (
a INT(11) NOT NULL,
b VARCHAR(255) DEFAULT NULL,
KEY idx_a(a),
KEY idx_b(b)
) ENGINE = INNODB DEFAULT CHARSET = utf8;
CREATE TABLE test_myisam (
id INT(11) NOT NULL AUTO_INCREMENT,
name VARCHAR(255) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE = MyISAM AUTO_INCREMENT = 2 DEFAULT CHARSET = utf8;我们创建两张表,分别是用InnoDB、MyISAM引擎;
使用InnoDB引擎,存储使用.ibd文件
使用MyISAM引擎,存储使用.myd、.myi文件

注意:在MySQL8.0之前两者都有.frm文件的,但是在8.0就都移除了。
MyISAM 与 InnoDB 区别(重点)
MyISAM
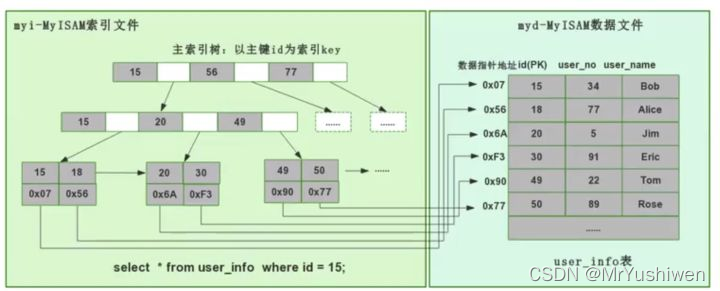
- MyISAM 用的是非聚集索引方式,即数据和索引落在不同的两个文件上。
- MyISAM 在建表时以主键作为 KEY 来建立主索引 B+树,树的叶子节点存的是对应数据的物理地址。
- 当我们为某个字段添加索引时,我们同样会生成对应字段的索引树,该字段的索引树的叶子节点同样是记录了对应数据的物理地址,然后也是拿着这个物理地址去数据文件里定位到具体的数据记录。
引用一张网络上面找到的图片来说明:
InnoDB
- InnoDB 是聚集索引方式,因此数据和索引都存储在同一个文件里。
- InnoDB 在建表时以主键作为 KEY 来建立主索引 B+树,树的叶子节点存的是主键ID和主键 ID 对应的数据。
- 当我们为某个字段添加索引时,我们同样会生成对应字段的索引树,但是该字段的索引树的叶子节点存储的是该字段所在行的主键KEY,拿到主键 KEY 后,再去查询一下主键索引树,才可以定位到具体数据;也就是会进行两次查找。

所以总的来说
MyISAM管理非事务表,提供高速存储和检索以及全文搜索能力,如果再应用中执行大量select操作,应该选择MyISAM。
InnoDB用于事务处理,具有ACID事务支持等特性,如果在应用中执行大量insert和update操作,应该选择InnoDB。
MySQL的索引分类
1. 按照功能划分
(1)普通索引
最最基础的索引,这种索引没有任何的约束作用,它存在的主要意义就是提高查询效率。
CREATE TABLE `user` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(64) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `name` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4;
KEY name(name)
name 字段就是一个普通索引(括号外面的是索引名,里边的是索引的字段)。
(2)唯一性索引
在普通索引的基础上增加了数据唯一性的约束,一张表中可以同时存在多个唯一性索引
CREATE TABLE `user` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(64) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `name` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4;UNIQUE KEY name(name)
name 字段就是唯一性索引
(3)主键索引
PRIMARY KEY (id)
主键索引则是在唯一性索引的基础上又增加了不为空的约束(换言之,添加了唯一性索引的字段,是可以包含 NULL 值的),即 NOT NULL+UNIQUE,一张表里最多只有一个主键索引,当然一个主键索引中可以包含多个字段。
(4)全文索引
全文索引其实我们很少在 MySQL 中用,如果项目中有做全文索引的需求,一般可以通过 Elasticsearch 或者 Solr 来做,目前比较流行的就是 Elasticsearch 了。
不过 MySQL 的全文索引并不好用,有这方面的需求还是直接上 ES 吧。
CREATE TABLE `user` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(64) DEFAULT NULL,
PRIMARY KEY (`id`),
FULLTEXT KEY `name` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4;FULLTEXT KEY name (name)
name 字段就是全文索引
2. 按照物理实现划分
(1)聚集索引(聚簇索引)
InnoDB的主键索引就是聚集索引。
注意对于InnoDB来说,只有主键索引是聚集索引,其它都是非聚集的!!!
聚集索引在存储的时候,按照主键来排序存储数据,B+Tree 的叶子结点就是完整的数据行,查找的时候,找到了主键也就找到了完整的数据行。
当我们基于 InnoDB 引擎创建一张表的时候,都会创建一个聚集索引,每张表都有唯一的聚集索引(3种情况):
- 如果这张表定义了主键索引,那么这个主键索引就作为聚集索引。
- 如果这张表没有定义主键索引,那么该表的第一个唯一非空索引作为聚集索引。
- 如果这张表也没有唯一非空索引,那么 InnoDB 内部会生成一个隐藏的主键作为聚集索引,这个隐藏的主键是一个 6 个字节的列,该列的值会随着数据的插入自增。
聚集索引最主要的优势就是查询快。如果要查询完整的数据行,使用非聚集索引往往需要回表才能实现,而使用聚集索引则能一步到位。
不过聚集索引也有一些劣势:
- 聚集索引可以减少磁盘 IO 的次数,这在传统的机械硬盘中是很有优势的,不过要是固态硬盘或者内存(有时候为了提高操作效率,数据库服务器会整一个比较大的内存),这个优势就不明显了。
- 聚集索引在插入的时候,最好是主键自增,自增主键插入的时候比较快,直接插入即可,不会涉及到叶子节点分裂等问题(不需要挪动其他记录);而其他非自增主键插入的时候,可能要插入到两个已有的数据中间,就有可能导致叶子节点分裂等问题,插入效率低(要挪动其他记录)。如果聚集索引在插入的时候不是自增主键,插入效率就会比较低。
(2)非聚集索引(非聚簇索引)
MyISAM的主键索引就是一种非聚集索引。

非聚集索引我们一般也称为二级索引或者辅助索引,对于非聚集索引,数据库会有单独的存储空间来存放。
非聚集索引在查找的时候要经过两个步骤。
select * from user where username='Tom' -- username 是非聚集索引- (假设 username 字段是非聚集索引),那么此时需要先搜索 username 这一列索引的 B+Tree,这个 B+Tree 的叶子结点存储的不是完整的数据行,而是主键值。
- 当我们搜索完成后得到主键的值,然后拿着主键值再去搜索主键索引的 B+Tree,就可以获取到一行完整的数据。(回表)
所以如果我们在查询中用到了非聚集索引,那么就会搜索两棵 B+Tree。
第一次搜索 B+Tree 拿到主键值后再去搜索聚集索引的 B+Tree,这个过程就是所谓的回表。
一张表只能有一个聚集索引,但可以有多个非聚集索引。
使用聚集索引的时候,数据的查询效率高,但如果对数据进行插入,删除,更新等操作,效率会比非聚集索引低。
为什么建议InnoDB表必须建主键?
在设计者设计InnoDB这种引擎的时候,ibd 文件必须要用一棵B+树来组织。
当我们这个表里面有主键的情况下,首先主键会自带主键索引,显然我们就可以用这个主键索引来组织这张表的数据。
当我们创建的表中没有主键索引,那么该存储引擎会帮我们挑选出一列不重复的数据,然后用这一列的索引数据来组织这一棵B+树。
但是如果这样的列如果不存在呢?换句话说就是不存在每个元素都不相同的列,怎么办?
MySQL会帮我们建立一列隐藏列,类似于我们oracle中使用的rowid一样,然后将其作为主键索引。
相信看到这里,优缺点大家已经一目了然了!这么简单的事情交给机器来做合适吗?机器万一挑错了怎么办?rowid那么长的一串字符会浪费多少空间? 所以这种小事情在我们一开始建表的时候就应该自己做好(主键索引在一开始创建表的时候,就要自己指定出来)
为什么推荐使用整型的自增主键?为什么不用UUID?
整型的原因
- 整形比字符串(UUID)省空间
- 整形判断大小比字符串(UUID)效率要高(字符串是比较ASCALL码)
自增的原因
如果我们的主键是自增的,那我们插入下一个节点的时候,这个节点的索引值肯定是要比已存在的所有索引值要大的。我们的存储引擎是B+树的结构,那我们只需要在最右下方的一个数据页中,新增一个节点即可。
但是如果我们设计的主键它不是自增的话,那我们插入下一个节点的时候,那这棵B+树很可能需要频繁的做平衡和节点分裂,非常浪费性能!!!
为什么非主键索引结构叶子节点存储的是主键值?
这个问题,看一下下面的这张图就可以明白了!
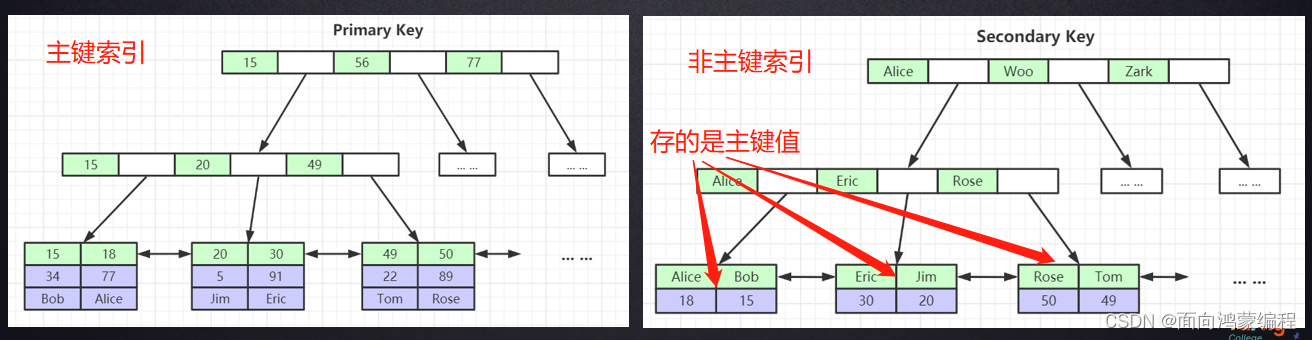
非主键索引(二级索引)没有必要放一整张表的数据,因为主键索引里面已经放了。找到主键索引然后再做一次“回表”操作就行了!
- 保证一致性
- 节省存储空间
联合索引的底层存储结构长什么样?
想要了解这个其实就会和 索引最左前缀原则底层实现原理 扯上关系!
只要我们的联合索引设计的好,其实可以通过三四个联合索引,将80%的SQL查询语句都覆盖到的!

以下那一条SQL会走索引?
-- 联合索引
KEY 'idx_name_age_position' ('name','age','position') USING BTREE;
-- 以下那一条SQL会走索引?
EXPLAIN SELECT * FROM employees WHERE name = 'Bill' and age = 30;
EXPLAIN SELECT * FROM employees WHERE age = 30 and position = 'dev';
EXPLAIN SELECT * FROM employees WHERE position = 31;显然,我们根据 索引最左前缀原则底层实现原理 可以知道只有第一条SQL会走索引!
至于为什么,我们以第二条SQL为例,首先我们知道该联合主键的('name','age','position')按这个顺序排序的,也就是他们在索引树中,先比较name字段,当name一样时,才会比较age字段,以此类推...
第二条SQL为什么没有走索引就很好解释了。当缺少name的时候,后面的字段已经是无序的了,根本就走不了索引。
所以我们想要搞清楚MySQL的索引,究其根本,还是要弄明白B+树这种数据结构,理解它的执行逻辑。