Vitis HLS 学习笔记--抽象并行编程模型-控制驱动与数据驱动
目录
1. 简介
2. Takeaways
3. Data-driven Task-level Parallelism
3.1 simple_data_driven 示例
3.2 分析 hls::task 类
3.3 分析通道(Channel)
3.4 注意死锁
4. Control-driven Task-level Parallelism
4.1 理解控制驱动的 TLP
4.2 simple_control_driven 示例
4.3 分析示例
4.4 DATAFLOW 规范形式
4.5 配置 DATAFLOW 的通道
5. 总结
1. 简介
当我们谈论任务级并行度(TLP)时,我们实际上是在讨论如何在应用程序中同时执行多个任务,以提高效率和性能。这就像是一个厨师在厨房里同时烹饪多道菜,而不是一道一道地做,这样可以更快地准备一顿大餐。
Vitis HLS 提供了两种典型的 TLP 模型:控制驱动的任务和数据驱动的任务。
数据驱动的模型就像是一个自动化的流水线,它不断地处理数据,不需要外部的指令或干预。只要有数据输入,它就会工作。这适用于那些不需要与外部存储器交互,且各个函数之间没有数据依赖关系的应用。简单来说,如果你的程序是一系列独立的步骤,每个步骤处理的数据都不会影响其他步骤,那么这种模型就很合适。
控制驱动的模型更像是有一个指挥官,根据需要调度任务和管理数据。如果你的应用程序的不同部分需要相互通信,或者一个任务的输出是另一个任务的输入,那么你就需要这种模型。Vitis HLS是一个工具,它可以帮助确定哪些任务可以同时进行,以及如何最有效地安排它们。
2. Takeaways
如果 HLS 设计为纯数据驱动的设计,且无需与软件应用进行任何交互,那么可以使用数据驱动的 TLP 模型来建模。
此类设计的典型应用场景有:
- 基于简单规则的“防火墙”,且“规则”编译到内核中。
- 快速傅里叶变换,且配置数据编译到内核中。
- FIR 滤波器,且系数编译到内核中。
如果设计需要往来外部存储器执行数据传输,那么可使用控制驱动的 TLP 模型。此类设计的示例有:
- 网络路由器,其中路由表必须完全更新后才能执行内核。
- 使用散列映射向服务器发送数据的负载均衡器,这类负载均衡器必须同时更新服务器列表、服务器映射以及对应的 IP 地址。
大部分设计将混用控制驱动与数据驱动的模型,需要对外部存储器进行部分访问,支持 HLS 内的并行任务与流水打拍任务之间的串流。
- 本文探讨的是函数级建模的方法(任务通道最优化或数据流最优化)。
- 达成良好的吞吐量的另一个关键要素是,指令级并行度。
- 指令级并行度指的是在循环、函数甚至阵列内部有效执行并行运算的能力。
3. Data-driven Task-level Parallelism
3.1 simple_data_driven 示例
#include "hls_task.h"void splitter(hls::stream<int>& in, hls::stream<int>& odds_buf,hls::stream<int>& evens_buf) {int data = in.read();if (data % 2 == 0)evens_buf.write(data);elseodds_buf.write(data);
}void odds(hls::stream<int>& in, hls::stream<int>& out) {out.write(in.read() + 1);
}void evens(hls::stream<int>& in, hls::stream<int>& out) {out.write(in.read() + 2);
}void odds_and_evens(hls::stream<int>& in, hls::stream<int>& out1,hls::stream<int>& out2) {hls_thread_local hls::stream<int, 5> s1; // channel connecting t1 and t2hls_thread_local hls::stream<int, 5> s2; // channel connecting t1 and t3// t1 infinitely runs func1, with input in and outputs s1 and s2hls_thread_local hls::task t1(splitter, in, s1, s2);// t2 infinitely runs func2, with input s1 and output out1hls_thread_local hls::task t2(odds, s1, out1);// t3 infinitely runs func3, with input s2 and output out2hls_thread_local hls::task t3(evens, s2, out2);
}3.2 分析 hls::task 类
对象声明:
- 在源代码中,hls::task 用于声明新对象,并配合 hls_thread_local 限定符使用。
- 这个限定符的关键作用是确保在函数(如 odds_and_evens)的多次实例化调用中,对象及其底层线程保持活跃状态。
- 在数据驱动模型中,无论是 C 语言仿真还是 RTL 仿真,hls_thread_local 都保证了一致的行为。
- 在 RTL 中,函数启动后将持续运行。
- 为了在 C 语言仿真中复现相同的行为,hls_thread_local 确保每个任务只启动一次,并且在多次调用中维持相同状态。
任务对象:
- 任务对象负责隐式地管理持续运行的函数线程。
- 向这些对象传递参数时,只能使用 hls::stream 或 hls::stream_of_blocks 类型。
系统不支持传递其他类型的参数。例如,不能直接将 even 这样的常量值作为函数的参数。如果需要在任务执行过程中使用常量,建议的做法是将相关函数设计为模板函数,并以模板参数的形式传递常量值。
任务主体:
- 提供的函数(例如示例中的 splitter/odds/evens)被称为任务主体。
- 这些函数被隐式无限循环包围,以确保任务保持运行并等待输入。
流水线循环:
- 提供的函数包含流水线循环。但是,为了防止死锁,需要将其设置为可刷新的流水线(FLP)。
- 工具会自动选择适用于给定流水线函数或循环的正确流水线样式。
3.3 分析通道(Channel)
通道由特殊模板化的 hls::stream(或 hls::stream_of_blocks)C++ 类进行建模。
通道具有以下属性:
- 在数据驱动的 TLP 模型中,hls::stream<type,depth> 对象的行为类似于具有指定深度的 FIFO。默认情况下,这些串流的深度为 2,但用户可以覆盖该值。
- 对这些串流的读取和写入是按顺序执行的。一旦从 hls::stream<> 中读取数据项,就无法再次读取该数据项。
- 串流可以在局部或全局范围内定义。全局作用域内定义的串流遵循与其他全局变量相同的规则。
- 对于这些串流(例如示例中的 s1 和 s2),hls_thread_local 限定符也是必需的。它确保在实例化函数(例如示例中的 odds_and_evens)的多次调用之间,相同的串流保持活动状态。
3.4 注意死锁
读取空串流属于阻塞读取,可能引发死锁,以下情况需要注意:
- 设计本身内部的进程的生产和耗用率不平衡,发生死锁。
- 测试激励文件提供的数据太少,不足以生成该测试激励文件在检查计算结果时所需的所有输出,发生死锁。
在 C 语言仿真期间:某个进程周期或者从顶层输入启动的进程链尝试读取空的通道,会导致死锁。
在 C/RTL 协同仿真期间以及在硬件 (HW) 中运行时:写入已满的通道或者读取空的通道,会导致死锁。
当设计包含 hls::task 时,Vitis HLS 工具会自动例化死锁检测器,检测到死锁后停止 C 语言仿真。使用 Vitis HLS GUI 可观察仿真的 hls::tasks 尝试读取空的通道时,所有发生阻塞的具体位置。
4. Control-driven Task-level Parallelism
4.1 理解控制驱动的 TLP
控制驱动的任务级并行(TLP) 是一种用于建模并行性的方法,它依赖于 C++ 中的顺序语义,而不是连续运行的线程。这种模型适用于以下情况:
- 按并发流水方式执行的函数:例如,在循环内部可以同时执行多个函数。
- 搭配实参执行的函数:这些实参不是通道,而是 C++ 中的标量或数组变量。这两种方式都适用于本地存储器和片外DDR存储器。
Vitis HLS 在保留原始 C++ 顺序执行行为的同时,引入了并行度的概念,具有以下特点:
- 后续函数可以在前一个函数完成之前启动。
- 函数可以在完成之前重新启动。
- 可以同时启动两个或两个以上的顺序函数。
控制驱动的 TLP ,也称数据流模型,它使用一系列顺序执行的函数来创建一个并行处理的流水线结构。这个结构允许多个任务同时进行:
任务级流水线架构:就像一个工厂流水线上的不同工位同时工作一样,数据流模型允许多个函数(任务)同时执行,每个函数处理不同的数据部分。
推断并行任务和通道:工具会自动识别哪些任务可以并行执行,并建立它们之间的通信通道。
DATAFLOW 指令:设计人员通过这些指令告诉工具哪些区域(函数体或循环主体)应该以数据流的方式来处理。
通道类型:设计人员可以选择不同类型的通道,比如 FIFO(hls::stream 或 #pragma HLS STREAM)或 PIPO(hls::stream_of_blocks),这些通道决定了数据的传输方式。
4.2 simple_control_driven 示例
#include <hls_stream.h>
#include <hls_vector.h>// Each vector will be 64 bytes (16 x 4 bytes)
typedef hls::vector<uint32_t, NUM_WORDS> vecOf16Words;
typedef unsigned int data_t;extern "C" {void diamond(vecOf16Words* vecIn, vecOf16Words* vecOut, int size) {
// The depth setting is required for pointer to array in the interface.
#pragma HLS INTERFACE m_axi port = vecIn depth = 32
#pragma HLS INTERFACE m_axi port = vecOut depth = 32hls::stream<vecOf16Words> c0, c1, c2, c3, c4, c5;assert(size % 16 == 0);#pragma HLS dataflowload(vecIn, c0, size);compute_A(c0, c1, c2, size);compute_B(c1, c3, size);compute_C(c2, c4, size);compute_D(c3, c4, c5, size);store(c5, vecOut, size);
}
}void load(vecOf16Words* in, hls::stream<vecOf16Words>& out, int size) {
Loop_Ld:for (int i = 0; i < size; i++) {
#pragma HLS performance target_ti = 32
#pragma HLS LOOP_TRIPCOUNT max = 32out.write(in[i]);}
}void compute_A(hls::stream<vecOf16Words>& in, hls::stream<vecOf16Words>& out1,hls::stream<vecOf16Words>& out2, int size) {
Loop_A:for (int i = 0; i < size; i++) {
#pragma HLS performance target_ti = 32
#pragma HLS LOOP_TRIPCOUNT max = 32vecOf16Words t = in.read();out1.write(t * 3);out2.write(t * 3);}
}void compute_B(hls::stream<vecOf16Words>& in, hls::stream<vecOf16Words>& out,int size) {
Loop_B:for (int i = 0; i < size; i++) {
#pragma HLS performance target_ti = 32
#pragma HLS LOOP_TRIPCOUNT max = 32out.write(in.read() + 25);}
}void compute_C(hls::stream<vecOf16Words>& in, hls::stream<vecOf16Words>& out,int size) {
Loop_C:for (data_t i = 0; i < size; i++) {
#pragma HLS performance target_ti = 32
#pragma HLS LOOP_TRIPCOUNT max = 32out.write(in.read() * 2);}
}
void compute_D(hls::stream<vecOf16Words>& in1, hls::stream<vecOf16Words>& in2,hls::stream<vecOf16Words>& out, int size) {
Loop_D:for (data_t i = 0; i < size; i++) {
#pragma HLS performance target_ti = 32
#pragma HLS LOOP_TRIPCOUNT max = 32out.write(in1.read() + in2.read());}
}void store(hls::stream<vecOf16Words>& in, vecOf16Words* out, int size) {
Loop_St:for (int i = 0; i < size; i++) {
#pragma HLS performance target_ti = 32
#pragma HLS LOOP_TRIPCOUNT max = 32out[i] = in.read();}
}4.3 分析示例
void diamond(data_t vecIn[100], data_t vecOut[100])
{data_t c1[100], c2[100], c3[100], c4[100];
#pragma HLS dataflowfuncA(vecIn, c1, c2);funcB(c1, c3);funcC(c2, c4);funcD(c3, c4, vecOut);
}
在以上示例中有 4 个函数:funcA,funcB,funcC 和 funcD。funcB 与 funcC 之间不存在任何数据依赖关系,因此可以并行执行:

funcA 会从非本地存储器 (vecIn) 读取,需首先执行。同样,funcD 写入非本地存储器 (vecOut),因此最后执行。
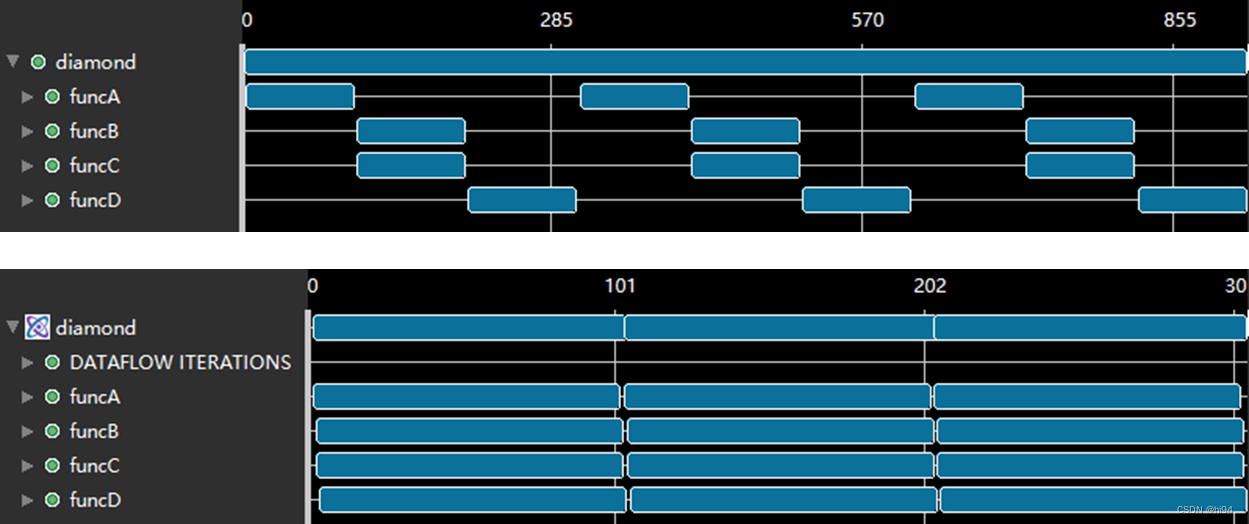
简单回顾:
- 通过 DATAFLOW 指令划定数据流区域。将某个特定区域(例如,函数体或循环主体)识别为要应用数据流模型的区域。
- 创建各通道。HLS 工具解析区域内函数体或循环体,并基于 C++ 变量(例如,标量、阵列或用户定义的通道,如 hls::streams 或 hls::stream_of_blocks)创建各通道,这些变量用于对数据流区域内的数据流动进行建模。
- 非标量变量。对于标量变量而言可能只是简单的 FIFO,而对于非标量变量,则可能是乒乓 (PIPO) 缓冲器,此类非标量变量有阵列、块串流(前提是需将 FIFO 和 PIPO 行为与块的显式锁定加以组合)等。
4.4 DATAFLOW 规范形式
为了增强数据流的可预测性,应遵循特定的代码编写规范。下面简明地概述了这些规范:
- 函数规范:
- 使用#pragma HLS dataflow指令以启用数据流优化。
- 定义的子函数可作为数据流的一部分,但不包括变量初始化和表达式的值传递。
- 确保按照规范格式编写代码,以便Vitis HLS能够有效实现数据流。如有偏差,使用GUI的数据流查看器和协同仿真时间轨迹进行验证。
示例代码:
void dataflow(Input0, Input1, Output0, Output1)
{
#pragma HLS dataflowUserDataType C0, C1, C2; // UserDataType can be scalars or arraysfunc1(Input0, Input1, C0, C1); // read Input0, read Input1, write C0, write C1func2(C0, C1, C2); // read C0, read C1, write C2func3(C2, Output0, Output1); // read C2, write Output0, write Output1
}- 循环内的数据流:
- 循环应仅包含一个函数调用,无其他代码。
- 循环变量应从0开始,以1递增,且上限为非负数。
- 数据流指令应位于循环体内。
示例代码:
void dataflow(Input0, Input1, Output0, Output1)
{for (int i = 0; i < N; i++){#pragma HLS dataflowUserDataType C0, C1, C2; // UserDataType can be scalars or arraysfunc1(Input0, Input1, C0, C1); // read Input0, read Input1, write C0, write C1func2(C0, C0, read C1, C2); // read C0, read C0, read C1, write C2func3(C2, Output0, Output1); // read C2, write Output0, writeOutput1}
}
4.5 配置 DATAFLOW 的通道
- 对于标量,Vitis HLS 将自动推断 FIFO 作为通道类型。
- 对于阵列,且始终顺序访问数据,PIPO/FIFO 均可作为通道。PIPO 从不发生死锁,但需要耗用更多存储器。FIFO 所需存储器较少,但存储深度配置不正确,则存在发生死锁的风险。
- 对于阵列,且需任意顺序访问数据,只能 PIPO 来实现(默认大小是原始阵列的两倍)。
void top ( ... ) {
#pragma HLS dataflowint A[1024];#pragma HLS stream type=pipo variable=A depth=3producer(A, B, …); // producer writes A and Bmiddle(B, C, ...); // middle reads B and writes Cconsumer(A, C, …); // consumer reads A and C
}
5. 总结
任务级并行度(TLP)通过同时执行多个任务提升应用效率和性能。Vitis HLS 提供了数据驱动和控制驱动两种 TLP 模型。数据驱动模型像自动化流水线,适用于无外部存储器交互且函数间无数据依赖的应用;控制驱动模型则更像一个指挥官,适合不同部分需相互通信的应用。数据驱动模型中,任务通过 hls::task 声明,通道通过 hls::stream 模拟,注意避免死锁。控制驱动模型使用 C++ 顺序语义创建并行处理流水线,任务级并行执行函数,需使用 DATAFLOW 编译指示。两者结合,实现高效并行计算。
