自然语言处理系列之: 句法分析
大纲
- 句法分析及其难点;
- 句法分析相关数据和技术;
- 基于Stanford Parser的句法分析实战
6.1 句法分析概述
-
句法分析(Parsing)定义
从单词串获取句法结构的过程,实现该过程的工具或程序叫做句法分析器(Parser)。分为完全句法分析和局部句法分析,完全句法分析以获取整个句子的句法结构为目的,而局部句法分析只关注局部成分,依存句法分析即为局部分析法的一种;
-
句法分析难点
- 歧义
- 搜索空间
-
方法分类
-
基于规则
处理大规模真实文本时,存在语法规则覆盖有限、系统可迁移差等问题;
-
基于统计
最典型的是PCFG(Probabilistic Context Free Grammar),本质是一套面向候选树的评价方法,给正确的句法树赋予一个较高分值不合理的句法树赋予一个较低分支,从而借用分值进行消歧;
-
6.2 句法分析的数据集与评测方法
-
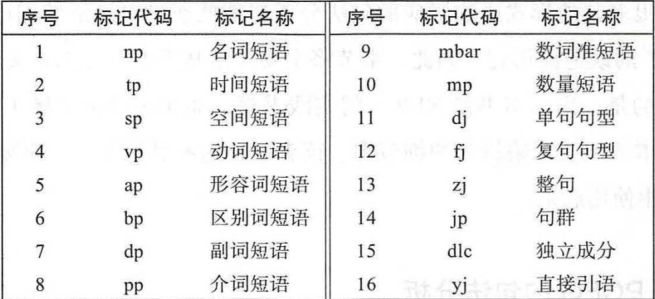
树库
- 英文:英文宾州树库(Penn TreeBank,PTB),前身为ATIS(Air Travel Information System)和WSJ(Wall Street Journa)
- 中文:中文宾州树库(Chinese TreeBank,CTB)、清华树库(Tsinghua Chinese TreeBank,TCT)、台湾中研院树库(Sinica TreeBank);
::: hljs-center
:::
-
评测方法
主要考虑满意度和效率两方面的性能,目前流行的是PARSEVAL评测体系,主要指标有准确率(分析正确的短语个数在句法分析结果中所占比例,即分析结果中与标准句法树相匹配的短语个数占分析结果中所有短语个数的比例)、召回率(分析得到的正确短语个数占标准分析树全部短语个数的比例)、交叉括号数(分析得到的某一短语覆盖范围与标准句法分析结果的某一短语的覆盖范围存在重叠而不存在包含关系,从而构成一个交叉括号);
6.3 句法分析的常用方法
-
基于PCFG的句法分析
一种生成式的上下文无关文法的扩展,短语结构文法表示为五元组(X,V,S,R,P):
- X:有限词汇的集合(词典),其元素称为词汇或终结符;
- V:有限标注的集合,称为非终结符集合;
- S:文法的开始符号,包含于 V V V,即 S ∈ V S\in V S∈V;
- R:有序偶对 ( α , β ) (\alpha,\beta) (α,β)的集合,即产生的规则集;
- P:每个产生规则的统计概率;
-
PCFG可解决的问题 :
- 计算分析树的概率值;
- 对于有多个分析树的句子,可依据概率值对所有分析树进行排序;
- 用于句法排歧,在多个分析结果中选择概率值最大的;
-
PCFG的三个基本问题
- 给定上下文无关文法 G G G,如何计算句子 S S S的概率,即如何求 P ( S ∣ G ) P(S|G) P(S∣G),利用内向和外向算法解决;
- 给定上下文无关文法 G G G以及句子 S S S,如何选择最佳句法树,即如何计算 a r g m a x T P ( T / S , G ) arg max_T P(T/S,G) argmaxTP(T/S,G),使用Viterbi算法解决;
- 如何为文法规则选参数,从而使训练句子的概率最大,即如何计算 a r g m a x G P ( S / G ) arg max_G P(S/G) argmaxGP(S/G),使用EM算法解决;
-
基于最大间隔马尔可夫网络(Max-Margin Markov Networks)的句法分析
f x ( x ) = a r g m a x y i n G ( x ) < w , ϕ ( x , y ) > f_x(x)=arg max_{y in G(x)}<w,\phi(x,y)> fx(x)=argmaxyinG(x)<w,ϕ(x,y)>
上式为最大间隔马尔可夫网络判别函数, ϕ ( x , y ) \phi (x,y) ϕ(x,y)表示与 x x x相对应的句法树 y y y的特征向量, w w w表示特征权重。通过采用多个独立且可并行训练的二分类器,每个二分类器识别一个短语标记,通过组合这些分类器完成句法分析任务,同时并行方式训练也提升了速度;
-
基于CRF的句法分析
相比于PCFG模型,主要不同在于概率计算方法和概率归一化的方式。CRF最大化的是句法树的条件概率值而非联合概率值,而且对概率进行归一化。也是一种判别式方法,需融合大量特征;
-
基于移进-归约(Shift-Reduce Algorithm)的句法分析模型
一种自下而上的方法,从输入串开始逐步进行归约,直到文法的开始符号,类似于下推自动机的LR分析法,最基本的数据结构式堆栈,主要涉及以下4种操作(S:句法树根节点):
- 移进:从句子左端将一个终结符一道栈顶;
- 归约:根据规则,将栈顶的若干个字符替换为一个符号;
- 接收:句子中所有词均移入栈中,栈中只剩一个符号 S S S,从而判定分析成功,结束;
- 拒绝:句子中所有词已进栈,栈中不止一个符号 S S S,也就无法进行任何归约操作,导致分析失败;
6.4 使用Stanford Parser的PCFG算法进行句法分析
-
Stanford Parser主要优点:
- 既是一个高度优化的概率上下文无关文法和词汇化依存分析器,又是一个词汇化上下文无关文法分析器;
- 以宾州树库作为分析器的训练数据,支持多语言;
- 提供多样化的分析输出形式,出句法分析树输出外,还支持分词、词性标注、短语结构、依存句法等输出;
- 内置分词、词性标注、基于自定义树库的分析器训练等辅助工作;
- 支持多平台,并封装了多种语言接口;
-
包下载链接
-
基于PCFG的中文句法分析实战
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @version : 1.0
# @Time : 2019-8-30 11:03
# @Author : cunyu
# @Email : cunyu1024@foxmail.com
# @Site : https://cunyu1943.github.io
# @File : pcfg_parser.py
# @Software: PyCharm
# @Desc : 使用Stanford Parser的PCFG算法进行句法分析
import jieba
from nltk.parse import stanford
import os
from nltk.tree import Tree
if __name__ == '__main__':
# 分词
string = "中华人民共和国成立于1949年,至今已有70周年"
seg_list = jieba.cut(string, cut_all=False, HMM=True)
seg_str = ' '.join(seg_list)
print(seg_str)
# PCFG句法分析
root = '/data/zhangliang/software/'
parser_path = root + 'stanford/stanford-parser.jar'
model_path = root + 'stanford/stanford-parser-3.9.2-models.jar'
# 指定jdk路径
if not os.environ.get('JAVA_HOME'):
JAVA_HOME = '/data/zhangliang/software/Java'
os.environ['JAVA_HOME'] = JAVA_HOME
# PCFG模型路径
pcfg_path = 'edu/stanford/nlp/models/lexparser/chinesePCFG.ser.gz'
parser = stanford.StanfordParser(path_to_jar=parser_path, path_to_models_jar=model_path, model_path=pcfg_path)
sentence = parser.raw_parse(seg_str)
for line in sentence:
print(line)