实时即未来,车联网项目之将数据落地到文件系统和数据库【三】
文章目录
- 实时读取流数据的步骤
- 原始数据实时ETL任务分析 Hive
- 将HDFS数据映射到Hive表
- 自定义Sink数据写入Hive表(了解)
- 原始数据实时ETL落地到HBase
- HBase的rowkey设计原则
- HBase的rowkey设计方法
- 正常数据落地到HBase
- 原始数据实时 ETL 任务 HBase 调优
- 数据写入HBase优化 - 客户端优化
- 数据写入HBase预分区
- 数据写入HBase预写日志
- 数据写入HBase使用压缩和编码
实时读取流数据的步骤
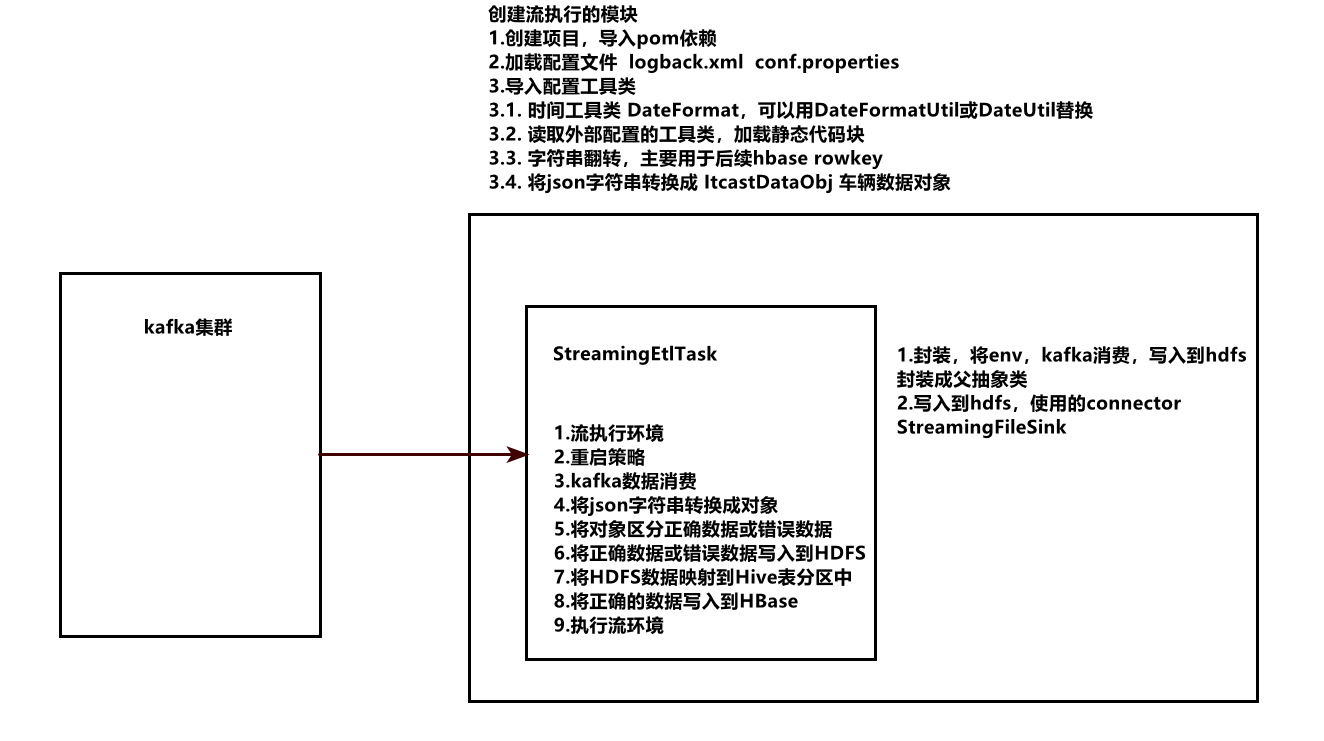
原始数据实时ETL任务分析 Hive
将HDFS数据映射到Hive表
-
需要指定的HDFS的目录

-
回忆如何映射HDFS数据到Hive表中
① 创建表 create external table maynor_src (…) row formate delimited field terminate by ‘\t’ partitioned by(dt string) location ‘hdfs://node01…/maynor_src’;
② 使用数据库
③ 添加文件夹到指定分区
alter table maynor_src add partition(dt=‘20210922’) location ‘hdfs://node01:8020/apps/warehouse/ods.db/maynor_src/20210922’
#!/bin/bash dt=`date -d '1 days ago' +'%Y%m%d'` tableName=$1 ssh node03 `/export/server/hive/bin/hive -e "use maynor_ods;alter table ${tableName} add partition(dt=${dt}) location 'hdfs://node01:8020/apps/warehouse/ods.db/${tableName}/${dt}"` -
如何实现从HDFS中正确或错误的数据映射到Hive表中
①
②
③
-
如何自动化HDFS数据到Hive表中
# 使用shell 脚本 alter table maynor_src add partition (dt="20210922") location "/apps/hive/warehouse/ods.db/maynor_src/20210922"; -
如何执行 t+1 离线任务,设置调度的两种方式
① crontab
linux 自带调度
② 调度平台
azkaban airflow dolphinscheduler oozie 自研
自定义Sink数据写入Hive表(了解)
-
实现步骤
package cn.maynor.streaming.sink; import cn.maynor.streaming.entity.maynorDataObj; import org.apache.flink.api.java.utils.ParameterTool; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.functions.sink.RichSinkFunction; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import java.sql.Connection; import java.sql.DriverManager; import java.sql.Statement; /** * Author maynor * Date 2021/9/22 10:02 * Desc 将每条车辆的数据直接写入到 Hive 中 */ public class SaveErrorDataHiveSink extends RichSinkFunction<maynorDataObj> { //定义 logger private static final Logger logger = LoggerFactory.getLogger(SaveErrorDataHiveSink.class); //2.创建有参构造方法,参数包括数据库名和表名 //定义变量 private String dbName; private String tableName; //定义连接对象和statement对象 private Connection conn = null; private Statement statement = null; //构造方法 public SaveErrorDataHiveSink(String _dbName,String _tableName){ this.dbName = _dbName; this.tableName = _tableName; } //3.重写open方法进行Hive连接的初始化 @Override public void open(Configuration parameters) throws Exception { //3.1 将JDBC驱动 org.apache.hive.jdbc.HiveDriver 加载进来 //获取全局参数 ParameterTool parameterTool = (ParameterTool) getRuntimeContext() .getExecutionConfig() .getGlobalJobParameters(); //获取当前上下文中 hive 的驱动 Class.forName(parameterTool.getRequired("hive.driver")); //3.2 设置JDBC连接Hive的连接器,端口为10000 conn = DriverManager.getConnection( parameterTool.getRequired("hive.url"), parameterTool.getRequired("hive.user"), parameterTool.get("hive.password") ); //3.3 创建Statement statement = conn.createStatement(); //3.4 定义 schemaAndTableExists 实现库不存在创建库,表不存在创建表 Boolean flag = schemaAndTableExists(dbName,tableName,statement); if(flag){ logger.info("当前数据库和表初始化成功!"); }else{ logger.warn("请检查数据库和表!"); } } //5.重写cloese方法 关闭连接 @Override public void close() throws Exception { if(!statement.isClosed())statement.close(); if(!conn.isClosed())conn.close(); } //4.重写invoke将每条数据 @Override public void invoke(maynorDataObj value, Context context) throws Exception { //4.1 编写SQL将数据插入到表中 // insert into maynor_error values('11111'); StringBuffer buffer = new StringBuffer(); buffer.append("INSERT INTO "+tableName); buffer.append(" VALUES('"); buffer.append(value.getErrorData()+"'"); //4.2 执行statement.executeUpdate 将数据直接落地到Hive表 statement.executeUpdate(buffer.toString()); } //6.定义 schemaAndTableExists 方法 create database if not exists库或表, execute,选择数据库 /** * 初始化数据库和数据表,如果初始化成功返回 true,否则 false * @param dbName * @param tableName * @param statement * @return */ private Boolean schemaAndTableExists(String dbName, String tableName, Statement statement) { //数据库是否存在 Boolean flag = true; try{ //初始化数据库 String createDBSQL="create database if not exists "+dbName; boolean executeDB = statement.execute(createDBSQL); if(executeDB){ logger.info("当前数据库创建成功"); flag = true; }else{ logger.info("当前数据库已经存在"); flag = true; } //初始化数据表 String createTableSQL = "use "+tableName+";create table if not exists "+tableName+" (json string) partition by dt" + " row formatted delimited field terminate by '\t' location '/apps/hive/warehouse/ods.db/maynor_error'"; boolean executeTable = statement.execute(createTableSQL); if(executeTable){ logger.info("当前数据库表创建成功"); flag = true; }else{ logger.info("当前数据表已经存在"); flag = true; } }catch (Exception ex){ logger.warn("初始化失败!"); flag = false; } return flag; } }
原始数据实时ETL落地到HBase
- 写入hbase的步骤和准备
- 写入的表名
- hbase的rowkey
- 写入的列簇 columnFamily
- 列名和列值
HBase的rowkey设计原则
① rowkey 的长度原则 , 16个字节
② rowkey 的散列原则 ,尽量保证离散
③ rowkey 的唯一原则 , rowkey不要一样
HBase的rowkey设计方法
① 加盐 —— 随机数
② Hash散列
③ 翻转字符串
正常数据落地到HBase
-
开启 HBase 集群
# 首先开启 hdfs ,zookeeper /export/server/hbase/start-hbase.sh -
进入到 HBase命令行
hbase shell -
创建HBase表 - maynor_src ,列簇为 cf
# 查看hbase所有表 list # 查看namespace(数据库) list_namespace # 创建数据表 hbase(main):005:0> create 'maynor_src','cf' # 查看表中的数据 scan 'maynor_src' -
开发步骤
//1.创建 SrcDataToHBaseSink类继承 RichSinkFunction<maynorDataObj> //2.创建一个有参数-表名的构造方法 //3.重写open方法 //3.1 从上下文获取到全局的参数 //3.2 设置hbase的配置,Zookeeper Quorum集群和端口和TableInputFormat的输入表 //3.3 通过连接工厂创建连接 //3.4 通过连接获取表对象 //4.重写close方法 //4.1 关闭hbase 表和连接资源 //5. 重写 invoke 方法,将读取的数据写入到 hbase //5.1 setDataSourcePut输入参数value,返回put对象 //6. 实现 setDataSourcePut 方法 //6.1 如何设计rowkey VIN+时间戳翻转 //6.2 定义列簇的名称 //6.3 通过 rowkey 实例化 put //6.4 将所有的字段添加到put的字段中
原始数据实时 ETL 任务 HBase 调优
数据写入HBase优化 - 客户端优化
- 为什么需要优化呢?
防止出现每条数据都读写 HBase 数据库,造成集群宕机和数据丢失。
-
批量写入需要使用的缓存对象 - BufferedMutator 写数据的原理
将数据按批次写入到 BufferedMutator 对象中,按时间或者按大小写入。
-
代码逻辑优化
BufferedMutatorParams params = new BufferedMutatorParams(TableName.valueOf(tableName)); params.writeBufferSize(10 * 1024 * 1024L); params.setWriteBufferPeriodicFlushTimeoutMs(5 * 1000L); //5.1 setDataSourcePut输入参数value,返回put对象 try { Put put = setDataSourcePut(value); mutator.mutate(put); //5.2 指定时间内的数据强制刷写到hbase mutator.flush(); }catch (Exception ex){ logger.error("写入到hbase失败:"+ex.getMessage()); } -
在主流程中将数据写入到 maynor_src
数据写入HBase预分区
-
预分区的概念
-
创建预分区的语法
数据写入HBase预写日志
-
预写日志的作用
-
memstore在HBase读写作用
数据写入HBase使用压缩和编码
-
编码压缩其实是对列数据的压缩
-
编码压缩的优势
①
②
③
-
编码类型
-
创建一个 fast_diff 编码的 maynor_src 表
alter 'maynor_src', { NAME => 'cf', DATA_BLOCKs_ENCODING => 'FAST_DIFF' } -
压缩算法
-
创建一个 gz 或 snappy 压缩的 maynor_src_gz 表
create 'maynor_src',{NAME => 'cf',COMPRESSION => 'gz'}create 'maynor_src_snappy', { NAME => 'cf', COMPRESSION => 'SNAPPY' } -
查看数据量大小