Keras学习记录之模型
Keras 是一个用 Python 编写的高级神经网络 API,它能够以 TensorFlow, CNTK, 或者 Theano 作为后端运行。
模型构造
API构造
Keras 的核心数据结构是 model,一种组织网络层的方式。最简单的模型是 Sequential 顺序模型,它由多个网络层线性堆叠。对于更复杂的结构,你应该使用 Keras 函数式 API,它允许构建任意的神经网络图。
Keras的模型构造十分简单,可以通过add来堆叠模型
from keras.models import Sequential
model = Sequential()
#可以通过add来堆叠模型
from keras.layers import Dense
model.add(Dense(units=64, activation='relu', input_dim=100))
model.add(Dense(units=10, activation='softmax'))
当然也可以通过将网络层实例的列表传递给 Sequential 的构造器,来创建一个 Sequential 模型:
from keras.models import Sequential
from keras.layers import Dense, Activation
model = Sequential([
Dense(32, input_shape=(784,)),
Activation('relu'),
Dense(10),
Activation('softmax'),
])
函数式构造
网络层的实例是可调用的,它以张量为参数,并且返回一个张量 输入和输出均为张量。
它们都可以用来定义一个模型(Model) 这样的模型同Keras 的 Sequential 模型一样,都可以被训练。
以一个全连接层为例:
from keras.layers import Input, Dense
from keras.models import Model
# 这部分返回一个张量
inputs = Input(shape=(784,))
# 层的实例是可调用的,它以张量为参数,并且返回一个张量
x = Dense(64, activation='relu')(inputs)
x = Dense(64, activation='relu')(x)
predictions = Dense(10, activation='softmax')(x)
# 这部分创建了一个包含输入层和三个全连接层的模型
model = Model(inputs=inputs, outputs=predictions)
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(data, labels) # 开始训练
所有的模型都可调用,就像网络层一样
利用函数式 API,可以轻易地重用训练好的模型:可以将任何模型看作是一个层,然后通过传递一个张量来调用它。注意,在调用模型时,不仅重用模型的结构,还重用了它的权重。
这里沿用的是上面的代码
x = Input(shape=(784,))
# 这是可行的,并且返回上面定义的 10-way softmax。
y = model(x)
这种方式能允许我们快速创建可以处理序列输入的模型。如只需一行代码,就将图像分类模型转换为视频分类模型,model模型被重用了。
from keras.layers import TimeDistributed
#TimeDistributed这个层还是比较难理解的。事实上通过这个层我们可以实现从二维像三维的过渡,甚至通过这个层的包装,我们可以实现图像分类视频分类的转化。
# 输入张量是 20 个时间步的序列,
# 每一个时间为一个 784 维的向量
input_sequences = Input(shape=(20, 784))
# 这部分将我们之前定义的模型应用于输入序列中的每个时间步。
# 之前定义的模型的输出是一个 10-way softmax,
# 因而下面的层的输出将是维度为 10 的 20 个向量的序列。
processed_sequences = TimeDistributed(model)(input_sequences)
Model 类继承
除了这两类模型之外,还可以通过继承 Model 类并在 call 方法中实现我们自己的前向传播,以创建你自己的完全定制化的模型,(Model 类继承 API 引入于 Keras 2.2.0)。
这里是一个用 Model 类继承写的简单的多层感知器的例子:
import keras
class SimpleMLP(keras.Model):
def __init__(self, use_bn=False, use_dp=False, num_classes=10):
super(SimpleMLP, self).__init__(name='mlp')
self.use_bn = use_bn
self.use_dp = use_dp
self.num_classes = num_classes
self.dense1 = keras.layers.Dense(32, activation='relu')
self.dense2 = keras.layers.Dense(num_classes, activation='softmax')
if self.use_dp:
self.dp = keras.layers.Dropout(0.5)
if self.use_bn:
self.bn = keras.layers.BatchNormalization(axis=-1)
def call(self, inputs):
x = self.dense1(inputs)
if self.use_dp:
x = self.dp(x)
if self.use_bn:
x = self.bn(x)
return self.dense2(x)
model = SimpleMLP()
model.compile(...)
model.fit(...)
网络层定义在 init(self, …) 中,前向传播在 call(self, inputs) 中指定。在 call 中,你可以指定自定义的损失函数,通过调用 self.add_loss(loss_tensor) (就像你在自定义层中一样)。
在类继承模型中,模型的拓扑结构是由 Python 代码定义的(而不是网络层的静态图)。这意味着该模型的拓扑结构不能被检查或序列化。因此,以下方法和属性不适用于类继承模型:
model.inputs 和 model.outputs。
model.to_yaml() 和 model.to_json()。
model.get_config() 和 model.save()。
关键点:为每个任务使用正确的 API。Model 类继承 API 可以为实现复杂模型提供更大的灵活性,但它需要付出代价(比如缺失的特性):它更冗长,更复杂,并且有更多的用户错误机会。如果可能的话,尽可能使用函数式 API,这对用户更友好。
多输入多输出模型
以下是函数式 API 的一个很好的例子:具有多个输入和输出的模型。函数式 API 使处理大量交织的数据流变得容易。
来考虑下面的模型。我们试图预测 Twitter 上的一条新闻标题有多少转发和点赞数。模型的主要输入将是新闻标题本身,即一系列词语,但是为了增添趣味,我们的模型还添加了其他的辅助输入来接收额外的数据,例如新闻标题的发布的时间等。 该模型也将通过两个损失函数进行监督学习。较早地在模型中使用主损失函数,是深度学习模型的一个良好正则方法。
模型结构如下图所示:
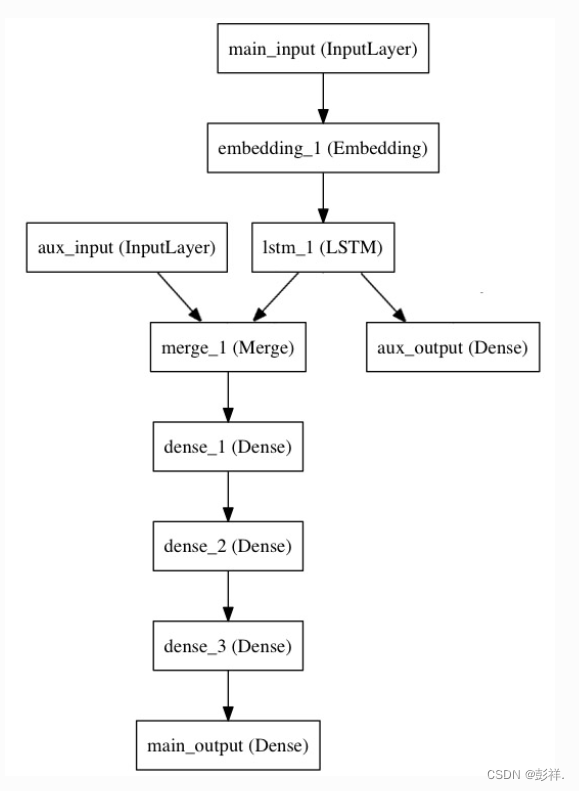
让我们用函数式 API 来实现它。
主要输入接收新闻标题本身,即一个整数序列(每个整数编码一个词)。 这些整数在 1 到 10,000 之间(10,000 个词的词汇表),且序列长度为 100 个词。
from keras.layers import Input, Embedding, LSTM, Dense
from keras.models import Model
# 标题输入:接收一个含有 100 个整数的序列,每个整数在 1 到 10000 之间。
# 注意我们可以通过传递一个 "name" 参数来命名任何层。
main_input = Input(shape=(100,), dtype='int32', name='main_input')
# Embedding 层将输入序列编码为一个稠密向量的序列,
# 每个向量维度为 512。
x = Embedding(output_dim=512, input_dim=10000, input_length=100)(main_input)
# LSTM 层把向量序列转换成单个向量,
# 它包含整个序列的上下文信息
lstm_out = LSTM(32)(x)
在这里,我们插入辅助损失,使得即使在模型主损失很高的情况下,LSTM 层和 Embedding 层都能被平稳地训练。
auxiliary_output = Dense(1, activation='sigmoid', name='aux_output')(lstm_out)
此时,我们将辅助输入数据与 LSTM 层的输出连接起来,输入到模型中:
auxiliary_input = Input(shape=(5,), name='aux_input')
x = keras.layers.concatenate([lstm_out, auxiliary_input])
# 堆叠多个全连接网络层
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x)
# 最后添加主要的逻辑回归层
main_output = Dense(1, activation='sigmoid', name='main_output')(x)
然后定义一个具有两个输入和两个输出的模型:
model = Model(inputs=[main_input, auxiliary_input], outputs=[main_output, auxiliary_output])
现在编译模型,并给辅助损失分配一个 0.2 的权重。如果要为不同的输出指定不同的 loss_weights 或 loss,可以使用列表或字典。 在这里,我们给 loss 参数传递单个损失函数,这个损失将用于所有的输出。
model.compile(optimizer='rmsprop', loss='binary_crossentropy',
loss_weights=[1., 0.2])
我们可以通过传递输入数组和目标数组的列表来训练模型:
model.fit([headline_data, additional_data], [labels, labels],
epochs=50, batch_size=32)
由于输入和输出均被命名了(在定义时传递了一个 name 参数),我们也可以通过以下方式编译模型:
model.compile(optimizer='rmsprop',
loss={'main_output': 'binary_crossentropy', 'aux_output': 'binary_crossentropy'},
loss_weights={'main_output': 1., 'aux_output': 0.2})
# 然后使用以下方式训练:
model.fit({'main_input': headline_data, 'aux_input': additional_data},
{'main_output': labels, 'aux_output': labels},
epochs=50, batch_size=32)
共享网络层
函数式 API 的另一个用途是使用共享网络层的模型。我们来看看共享层。
来考虑推特推文数据集。我们想要建立一个模型来分辨两条推文是否来自同一个人(例如,通过推文的相似性来对用户进行比较)。
实现这个目标的一种方法是建立一个模型,将两条推文编码成两个向量,连接向量,然后添加逻辑回归层;这将输出两条推文来自同一作者的概率。模型将接收一对对正负表示的推特数据。
由于这个问题是对称的,编码第一条推文的机制应该被完全重用来编码第二条推文(权重及其他全部)。这里我们使用一个共享的 LSTM 层来编码推文。
让我们使用函数式 API 来构建它。首先我们将一条推特转换为一个尺寸为 (280, 256) 的矩阵,即每条推特 280 字符,每个字符为 256 维的 one-hot 编码向量 (取 256 个常用字符)。
import keras
from keras.layers import Input, LSTM, Dense
from keras.models import Model
tweet_a = Input(shape=(280, 256))
tweet_b = Input(shape=(280, 256))
要在不同的输入上共享同一个层,只需实例化该层一次,然后根据需要传入你想要的输入即可:
# 这一层可以输入一个矩阵,并返回一个 64 维的向量
shared_lstm = LSTM(64)
# 当我们重用相同的图层实例多次,图层的权重也会被重用 (它其实就是同一层)
encoded_a = shared_lstm(tweet_a)
encoded_b = shared_lstm(tweet_b)
# 然后再连接两个向量:
merged_vector = keras.layers.concatenate([encoded_a, encoded_b], axis=-1)
# 再在上面添加一个逻辑回归层
predictions = Dense(1, activation='sigmoid')(merged_vector)
# 定义一个连接推特输入和预测的可训练的模型,输入头尾即可
model = Model(inputs=[tweet_a, tweet_b], outputs=predictions)
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
model.fit([data_a, data_b], labels, epochs=10)
让我们暂停一会,看看如何读取共享层的输出或输出尺寸。
层「节点」的概念(判断多个输入变量的层的形状)
每当你在某个输入上调用一个层时,都将创建一个新的张量(层的输出),并且为该层添加一个「节点」,将输入张量连接到输出张量。当多次调用同一个图层时,该图层将拥有多个节点索引 (0, 1, 2…)。
在之前版本的 Keras 中,可以通过 layer.get_output() 来获得层实例的输出张量,或者通过 layer.output_shape 来获取其输出形状。现在你依然可以这么做(除了 get_output() 已经被 output 属性替代)。但是如果一个层与多个输入连接呢?
只要一个层仅仅连接到一个输入,就不会有困惑,.output 会返回层的唯一输出:
a = Input(shape=(280, 256))
lstm = LSTM(32)
encoded_a = lstm(a)
assert lstm.output == encoded_a
但是如果该层有多个输入,那就会出现问题:
a = Input(shape=(280, 256))
b = Input(shape=(280, 256))
lstm = LSTM(32)
encoded_a = lstm(a)
encoded_b = lstm(b)
lstm.output
>> AttributeError: Layer lstm_1 has multiple inbound nodes,
hence the notion of "layer output" is ill-defined.
Use `get_output_at(node_index)` instead.
好吧,通过下面的方法可以解决:
assert lstm.get_output_at(0) == encoded_a
assert lstm.get_output_at(1) == encoded_b
够简单,对吧?
input_shape 和 output_shape 这两个属性也是如此:只要该层只有一个节点,或者只要所有节点具有相同的输入/输出尺寸,那么「层输出/输入尺寸」的概念就被很好地定义,并且将由 layer.output_shape / layer.input_shape 返回。但是比如说,如果将一个 Conv2D 层先应用于尺寸为 (32,32,3) 的输入,再应用于尺寸为 (64, 64, 3) 的输入,那么这个层就会有多个输入/输出尺寸,你将不得不通过指定它们所属节点的索引来获取它们:
a = Input(shape=(32, 32, 3))
b = Input(shape=(64, 64, 3))
conv = Conv2D(16, (3, 3), padding='same')
conved_a = conv(a)
# 到目前为止只有一个输入,以下可行:
assert conv.input_shape == (None, 32, 32, 3)
conved_b = conv(b)
# 现在 `.input_shape` 属性不可行,但是这样可以:
assert conv.get_input_shape_at(0) == (None, 32, 32, 3)
assert conv.get_input_shape_at(1) == (None, 64, 64, 3)
模型参数
指定输入数据的尺寸
模型需要知道它所期望的输入的尺寸。出于这个原因,顺序模型中的第一层(且只有第一层,因为下面的层可以自动地推断尺寸)需要接收关于其输入尺寸的信息。有几种方法来做到这一点:
- 传递一个 input_shape 参数给第一层。它是一个表示尺寸的元组 (一个由整数或 None 组成的元组,其中
None 表示可能为任何正整数)。在 input_shape 中不包含数据的 batch 大小。 - 某些 2D 层,例如 Dense,支持通过参数 input_dim 指定输入尺寸,某些 3D 时序层支持 input_dim 和input_length 参数。
- 如果你需要为你的输入指定一个固定的 batch 大小(这对 stateful RNNs 很有用),你可以传递一个 batch_size
参数给一个层。如果你同时将 batch_size=32 和 input_shape=(6, 8) 传递给一个层,那么每一批输入的尺寸就为
(32,6,8)。
因此,下面的代码片段是等价的:
model = Sequential()
model.add(Dense(32, input_shape=(784,)))
model = Sequential()
model.add(Dense(32, input_dim=784))